ANKARA ÜNİVERSİTESİ
FEN BİLİMLERİ ENSTİTÜSÜ
YÜKSEK LİSANS TEZİ
NORMAL DAĞILIM VE NORMAL DAĞILIMLA İLGİLİ ÇIKARIMLAR
Şenol ÇELİK
İSTATİSTİK ANABİLİM DALI
ANKARA
2006
Her hakkı saklıdır
ÖZET
Yüksek Lisans Tezi
NORMAL DAĞILIM VE NORMAL DAĞILIMLA İLGİLİ ÇIKARIMLAR
Şenol ÇELİK
Ankara Üniversitesi
Fen Bilimleri Enstitüsü
İstatistik Anabilim Dalı
Danışman : Doç. Dr. Fahrettin ARSLAN
Bu tezin amacı, normal dağılımlı rasgele vektörlerin karesel formlarını ve dağılımlarını
araştırmak, karesel formların yapısını ve normal dağılımla olan ilişkisinden yararlanarak
özelliklerini görmek ve istatistiksel sonuçlar çıkarmaktır.
Normal dağılım istatistikte en önemli dağılım olarak bilinmektedir. Normal dağılımla
ilgili olarak hala çok sayıda araştırmalar yapılmaya devam edilmektedir.
Bu çalışmada, karesel formların incelenmesine normal dağılımdan yola çıktığımız için
normal dağılımla ilgili bilinen özelliklerini ifade ettik. Normal dağılımdan elde edilen
dağılımlar ve aralarındaki ilişki ele alındı.
Son olarak karesel formların dağılım özelliğinden yararlanarak F dağılımı ele alındı.
Ankara Üniversitesi Türkçe ve Yabancı Dil Araştırma ve Uygulama Merkezi (TÖMER)
tarafından yapılan lisansüstü yabancı dil sınavına giren öğrencilerin sınavdaki başarı
notları F testi ile incelendi. Fen Bilimleri, Sağlık Bilimleri, Sosyal Bilimler ve Eğitim
Bilimleri Enstitüsüne müracaat eden öğrencilerin sınavdaki başarı notları ortalamaları
arasındaki anlamlı farklılık olup olmadığı test edildi.
2006, 91 sayfa
Anahtar Kelimeler : Normal dağılım, rasgele vektörler, limit dağılımı, karesel formlar,
Ki-kare dağılımı, t dağılımı, F dağılımı, Varyans Analizi.
i
ABSTRACT
Master Thesis
NORMAL DISTRIBUTION AND RELATED OBTAINMENT FOR THE NORMAL
DISTRIBUTION
Şenol ÇELİK
Ankara University
Graduate School of Natural and Applied Sciences
Department of Statistics
Supervisor: Assoc. Prof. Dr. Fahrettin ARSLAN
Purpose of this thesis is to investigate quadratic forms of random vectors with normal
distributions and their distribution, to see the structure of quadratic forms and their
properties by means of the relation of normal distribution and to generate statistical
results.
Normal distribution has known the most important distribution in statistics. Many
researches have been continued interest with normal distribution.
In this work, we examined quadratic forms and expressed their properties with normal
distribution. Distributions were provided from normal distributions and between their
relations were considered.
Finally, F distribution was considered to benefit from distribution properties of
quadratic forms. The marks of students entered to postgraduate foreign language exam,
in Ankara University Turkish and Foreign Language Research and Application Center,
were investigated with F test. Whether significant differences or not among marks of
students whom of refer to Graduate School of Natural and Applied Sciences, Graduate
School of Health and Applied Sciences, Graduate School of Social and Applied
Sciences, Graduate School of Education and Applied Sciences among in the exam was
tested.
2006, 91 pages
Key Words: Normal distribution, random vectors, limiting distributions, quadratic
forms, chi-square distribution, t distribution, F distribution, Analysis of Variance.
ii
TEŞEKKÜR
Beni çalışmalarımın her safhasında yakın ilgi ve önerileri ile destekleyen ve katkıda
bulunan danışman hocam Sayın Doç. Dr. Fahrettin ARSLAN’a (Ankara Üniversitesi
Fen Fakültesi), akademik öğrenim boyunca desteklerini gördüğüm Sayın Prof. Dr.
Yalçın TUNCER’e (Ankara Üniversitesi Fen Fakültesi) ve Prof. Dr. Fikri ÖZTÜRK’e
(Ankara Üniversitesi Fen Fakültesi) ve bana çeşitli konularda destek sağlayan
bölümümüzdeki diğer tüm hocalarıma, ayrıca benim
yüksek lisans tezinin
yürütülmesinde iş yerimden izin veren amirlerime ve arkadaşlarıma sonsuz
teşekkürlerimi sunarım.
Şenol ÇELİK
Ankara, Ocak 2006
iii
İÇİNDEKİLER
ÖZET……………………………………………………………………………...……..i
ABSTRACT………………………………………………………………………….....ii
ÖNSÖZ ve EŞEKKÜR………………………………………………………………...iii
SİMGELER DİZİNİ……………………………….…………………………………vii
ŞEKİLLER DİZİNİ………………………………….………………………………viii
ÇİZELGELER DİZİNİ……………………………………………………………….xi
1.GİRİŞ……………………………………………………………………….................1
1.1 Normal Dağılımın Tarihçesi…………………………………….………................2
2. NORMAL DAĞILIM FONKSİYONU…………………………………………….3
2.1 Normal Dağılımın yapısı…………………………………………………………...3
2.1.1 Herschel tanımlaması…………………………………………………...….…….3
2.1.2 Maxwell tanımlaması…………………………………...……………..................6
2.1.3 Hagen tanımlaması…………………………………………………….................7
2.1.4 Olasılık yoğunluk fonksiyonu f olan bir dağılımın entropisi…………..…….8
2.1.5 Matematiksel tanımlama………………………………………….…….……….8
2.2 Normal Dağılımın Özellikleri…………………..………………………………...10
2.3 Normal Dağılım İçin Uygunluk Testleri…………………………………….…...11
2.3.1 Q-Q Nokta Grafik Yöntemi…………..………………………………….……..12
2.3.2 Çeyreklikler arası fark yardımıyla oluşan test………….………………….....13
2.3.3 Ki-Kare Uygunluk Testi…………………………………………….………......13
2.3.4 Kolmogorov-Simirnov Uygunluk testi…………………………...…………….14
2.3.5 Lilliefors Normallik Testi…………………………………………………….....15
2.3.6 Shapio-Wilk Normallik testi………………………………………………..…..16
2.3.7 İki ve daha fazla değişken için normallik testleri………………….…..……...17
2.4 Beklenen Değer……………………………………………………..……………..17
2.5 Varyans…………………………………………………………..………………...18
2.6 Moment Çıkaran Fonksiyon………………………………………………..…….18
2.7 Normal Dağılım İçin Bazı Önemli Teoremler……….………..……………..…..19
2.8 Yakınsama Teoremleri………...……………………………………..…………...22
2.9 İki Değişkenli Normal Dağılım…………...…………………………..…………..23
iv
2.10 Çok Değişkenli Normal Dağılım…………………………..………………...…..25
2.10.1 Çok Değişkenli Normal Dağılımın Beklenen Değeri ve Kovaryansı……......26
2.10.2 Çok Değişkenli Normal Dağılımdan çıkarılacak bazı sonuçlar…….....…....27
2.10.3 Çok Değişkenli Koşullu Dağılımlar ………………………..……………........32
2.10.4 Çok Değişkenli Normal Dağılımın Moment Çıkaran Fonksiyonu….....……34
3. NORMAL DAĞILIMIN DİĞER DAĞILIMLARLA İLİŞKİSİ………..………35
3.1 Stokastik Yakınsama…………...………………………………..………………..35
3.2 Moment Çıkaran Fonksiyon Yaklaşımı………………………..………………..36
3.3 Ki-kare Dağılımının Normal Dağılıma Yaklaşımı………………..…………......36
3.4 t Dağılımının Normal Dağılıma Yaklaşımı …………….…………..……….….39
3.5 Asimptotik Normal Dağılım……………………………………..…………….....39
3.6 Stokastik Yakınsamanın Özellikleri……………….…………..…………...……40
3.7 Limit Teoremleri…………...……………………………………..…………….....41
4. NORMAL DAĞILIMDAN ELDE EDİLEN ÖNEMLİ SONUÇLAR….…….....44
4.1 Ki-Kare Dağılımı……………………………………………………..……….......44
4.2 t Dağılımı…………………………………………………………..……………...47
4.3 F – Dağılımı………………………………………………………………..………48
4.4 Wishart Dağılımı………………………………………………………….…….....49
5. KARESEL FORMLAR………...………………………………………..………...52
5.1 Karesel Formların Dağılımı……………………………..…………………..…....54
5.2 Faktör, faktör düzeyleri ve işlemler………………………..…………..………...60
5.3 Tek yönlü Varyans Analizi ve Lineer Model (Tam Ranklı Olmayan Model)...60
5.4 Hata Terimleri Kareler Toplamı….………………………………..………….…64
5.5 Toplam (Genel) Kareler Toplamının parçalara ayrılması……..….……..…....65
5.6 Dağılım özellikleri……………………………………………..………….……….66
5.7 Çoklu karşılaştırmalar…………………………………………………..………..69
5.7.1 Student Newman-Keuls testi…………………………………………..………..69
5.7.2 Duncan Testi…..……….……………………………………………..………....71
5.7.3 Scheffe Testi…... …..……………………..…………………..………..………..71
6. UYGULAMA..………………… …….. ..……………………………………….…73
7. TARTIŞMA VE SONUÇ……………..….………………..……..…………….......87
KAYNAKLAR..……………………..………………..……………..………………...89
v
ÖZGEÇMİŞ..……………………..………………..…………….……………………91
vi
SİMGELER DİZİNİ
R
Reel sayılar
E(.)
“.” nın beklenen değeri
V(.)
“.” nın varyansı
Cov (.,.)
“.,.” nın kovaryansı
F(.)
“.” nın dağılım fonksiyonu
f (.)
“.” nın olasılık yoğunluk fonksiyonu
J
Jacobian’ın determinantı
M X (t )
Moment çıkaran fonksiyon
~
“.” nın dağılımı
ρ
korelasyon katsayısı
χ 2 (.)
“.” Serbestlik dereceli ki-kare dağılım
N (.,.)
“. Ortalamalı, . varyanslı” normal dağılım
t(.)
“.” Serbestlik dereceli t dağılım
Frk
r ve k serbestlik dereceli F dağılımı
∑
Çok değişkenli normal dağılımın kovaryans matrisi
G
Genelleştirilmiş inversler
GİKT
Gruplar İçi (Hata Terimleri) Kareler Toplamı
GAKT
Gruplar Arası Kareler Toplamı
GKT
Genel Kareler Toplamı
GİKO
Gruplar İçi Kareler Ortalaması
GAKO
Gruplar Arası Kareler Ortalaması
ANOVA
Tek Yönlü Varyans Analizi
vii
ŞEKİLLER DİZİNİ
Şekil 2.1 Kutupsal koordinatların grafikle gösterilişi……….….………………………..9
Şekil 2.2 Normal Olasılık Yoğunluk Fonksiyonu Grafiği……….………………..……11
viii
ÇİZELGELER DİZİNİ
Çizelge 5.1 Y = X β + ε modelinin parametreleri……….………………..…...............62
Çizelge 5.2 Y = X β + ε modeline uygun varyans analizi çizelgesi…………………...67
Çizelge 6.1 Ankara Üniversitesi Yüksek Lisans-Doktora sınavına müracaat eden
öğrencilerin yabancı dil sınavından aldıkları puanlar………………….....75
Çizelge 6.2 Yüksek Lisans ve Doktora sınavlarına giren öğrencilerin yabancı dil
sınavı başarı notlarının toplam ve ortalama değerleri…………………...79
Çizelge 6.3 Ankara Üniversitesi Lisansüstü Yabancı Dil sınavına giren öğrencilerin
başarı notlarına ilişkin Y = X β + ε modeline uygun Varyans
Analizi çizelgesi…..……………………...………………………….........84
Çizelge 6.4 Ankara Üniversitesi Lisansüstü Yabancı Dil sınavına giren öğrencilerin
başarıları arasındaki anlamlı farklılığın Scheffe testi ile çoklu
karşılaştırılması. …………………...……………………...………………86
ix
1. GİRİŞ
Normal dağılım istatistikte en önemli dağılımlardan biridir. Uygulama alanı en fazla
olan ve üzerinde en fazla araştırma yapılan
ve teorik olarak da bütün özellikleri
itibarıyla en fazla kullanılan dağılımdır. Normal dağılımın diğer olasılık dağılımlarla
önemli ilişkileri vardır. Normal dağılımın tarihçesi, uygulama alanları, oluşumu,
özellikleri ve önemli teoremleri genel olarak verilmiştir.
Normal dağılımlar yardımıyla elde edilen olasılık dağılımları, araştırmacılar için deney
veya gözlemlerden yararlanarak istatistiksel çıkarımlar elde etmesi açısından yol
gösterici olmaktadır.
Karesel formlar normal dağılımdan elde edilen önemli sonuçlardan biridir. Bu
çalışmada normal dağılımdan oluşacak çıkarımlar ve normal dağılımlı rasgele
vektörlerin karesel formlarıyla ilgilenileceği için normal dağılımla ilgili bilinen
özelliklerin bilinmesi gerekir. Normal dağılım ile ilişkisinden yararlanarak karesel
formların dağılımından istatistiksel sonuç çıkarılacaktır. Teorik olarak ele alınan karesel
formların bütün özellikleri uygulama yapılarak daha açık bir şekilde ifade edilebilir.
Normal dağılımdan elde edilen dağılımlar, karesel formların yapısını ve özelliklerini
belirtmede etkin bir rol oynamaktadır. Bir rasgele değişken normal dağılmamışsa,
normal dağılıma yaklaşımı sağlanabilir. Bu da limit dağılımı yardımıyla mümkün
olmaktadır. Karesel formlar işlemlerin karmaşık olmaması nedeniyle uygulama
yapmaya çok elverişlidir.
Karesel formlarda diskriminant hesapları yapılabilmektedir. İki karesel form uygun bir
dönüşüm ile birbirlerine dönüşüyorsa, aynı sayıları temsil ederler.
1
1.1 Normal Dağılımın Tarihçesi
18. yüzyılda bir istatistikçi ve risk danışmanı olan Abraham De Moivre çok fazla sayıda
düzgün para atma denemeleri yapmıştır. Bunun sonucunda elde ettiği düzgün eğri şekil
olarak Binom Dağılımına yaklaşmıştır.
De Moivre, bu eğri için matematiksel ifadeleri daha önce bulabilseydi, n defa para
atarak m veya daha fazla tura veya yazı gelme olasılığını bulma problemini daha kolay
çözebilecekti. Bu amaçla normal dağılım denilen eğriyi keşfetti.
Normal dağılıma yakınsama, birçok doğal olayların dağılımı sonucunda önem
kazanmaktadır. Astronomik gözlemlerle yapılan ölçüm hatalarının analizi normal
dağılımın ilk uygulamalarından biridir. Ölçüm hataları, kusurlu gözlemlerden dolayı
meydana gelmiştir.
Galileo 17. yüzyılda bu hataların simetrik olduğunu ve küçük hataların büyük
hatalardan daha sıklıkla meydana geldiğini belirtmiştir.
Çok sayıdaki deneyden elde edilen ölçümlerin gerçek değerlerden farklarının
değişiminde önemli bir benzerlik gözlenmiştir. Ölçme hatalarındaki değişimin çan
şeklinde sürekli bir eğriye uyduğu tespit edilince, buna hataların normal eğrisi
denmiştir.
Son derece önemli olan Merkezi Limit Teoremi türetildiğinde, aynı dağılım 1778
yılında Laplace tarafından keşfedilmişti. 1808 yılında matematikçi Adrian ve 1809
yılında Gauss “Normal Dağılım” için bu teoremi geliştirdi (Lane 2003).
2
2. NORMAL DAĞILIM FONKSİYONU
Bu bölümde tek ve çok değişkenli normal dağılımın bilinen fakat bu çalışma için önem
arz eden bir takım özelliklerine kısaca değineceğiz. Bunun için de normal dağılımın
çeşitli tanımlarını aşağıdaki şekilde ifade edeceğiz. Bu tanımlar normal dağılımın nasıl
ortaya çıktığını ve nasıl meydana geldiğini açıklamakta yardımcı olacaktır.
2.1 Normal Dağılımın Yapısı.
Bu kısımda normal dağılımın çeşitli şekillerde verilen tanımlarını aşağıda göreceğiz.
Bunlar da,
1. Herschel tanımlaması
2. Maxwell tanımlaması
3. Hagen tanımlaması
4. Olasılık yoğunluk fonksiyonu f olan bir dağılımın entropisi
5. Matematiksel tanımlama
2.1.1 Herschel Tanımlaması
Bir x, y koordinat sisteminin başlangıç noktasındaki hedefe atış yapılırsa (X,Y)
koordinatlı noktaya düştüğünü düşünelim. (X,Y) koordinatları atışın hedeften sapmasını
belirtir. Bu durumda gerekli varsayımlar şunlardır:
a) X ve Y hataları birbirinden bağımsız ve bunların marjinal dağılımlarının olasılık
yoğunluk fonksiyonları süreklidir.
b) ( x, y ) noktasındaki olasılık yoğunluğu, bu noktanın hedefe olan uzaklığı ise
r = x 2 + y 2 ye bağlıdır.
c) ( x, y ) yönündeki hatalar bağımsızdır.
3
( x, y ) noktasındaki yoğunluk için, f ( x)q ( y ) = s (r ) fonksiyonel denklemi yazılabilir.
X’in olasılık yoğunluk fonksiyonu olan f fonksiyonunu bulmamız gerekmektedir.
ϕ ( x) = ln
f ( x)
şeklinde tanımlanırsa
f (0)
x = 0 için,
f (0)q ( y ) = s ( y ) ⇒
q( y ) s( y )
=
q (0) s (0)
y = 0 için,
f ( x)q (0) = s ( x) ⇒
f ( x) s( x)
=
f (0) s (0)
ve
f ( x) q( y ) s(r )
=
olmak üzere
f (0) q (0) s (0)
ln
f ( x)
q( y )
s(r )
+ ln
= ln
f (0)
q (0)
s (0)
ϕ ( x) + ϕ ( y ) = ϕ (r ) ,
r 2 = x2 + y2
olur. Bununla birlikte
x 2 = x12 + x22
ϕ (r ) = ϕ ( y ) + ϕ ( x1 ) + ϕ ( x2 ) ,
r 2 = y 2 + x12 + x22
ve genel olarak
ϕ (r ) = ϕ ( x1 ) + ϕ ( x2 ) + ... + ϕ ( xk ) ,
∑x
2
i
= r2
k = n 2 seçerek ve x = x1 = ... = xk ifadesini fonksiyonda yerine koyarak
ϕ (nx) = n 2ϕ ( x)
veya x =1 için
ϕ (n) = n2ϕ (1)
dir.
x=
m
rasyonel sayısı için, n ≠ 0 .
n
4
m
m
n 2ϕ = ϕ n. = ϕ (m) = m 2ϕ (1)
n
n
veya
m
m
ϕ = c
n
n
2
olur. Burada c = ϕ (1) ’dir.
ϕ ( x) = ϕ (1) x 2 dir. Burada ϕ süreklidir.
ϕ ( x) = cx 2 şeklinde bir fonksiyon ortaya çıkar. Bu fonksiyon,
f ( x) = f (0)ecx
2
şeklinde olur. f fonksiyonunun bir olasılık yoğunluk fonksiyonu olması için c sabitinin
negatif olması gerekir. c sabitini σ 2 sabitine bağlı olarak da ifade edebiliriz.
O zaman c = −
∞
∫
−
f (0)e
1
2σ 2
x2
1
2σ 2
biçiminde ifade edersek,
dx = 1 den,
−∞
f (0) =
1
2πσ
elde edilir. Bu şekilde meydana gelen normal olasılık yoğunluk fonksiyonu
1
− 2 x2
1
2σ
e
, −∞ < x < ∞
f ( x) = 2πσ
0
, diğer hallerde
(2.1)
biçiminde bulunur. Aynı yoldan, Y için
1
− 2 y2
1
2σ
e
, −∞ < y < ∞
q ( y ) = 2πσ
0
, diğer hallerde
(2.2)
biçiminde elde edilir.
X ve Y nin ortak olasılık yoğunluk fonksiyonu f ( x)q ( y ) olsun. x ekseni ile θ açısı
yapan ve başlangıç noktasından geçen bir doğru boyunca yapılan atış sonuçlarının
hedefe olan uzaklığı,
U = X cos θ + Y sin θ olsun.
U nun olasılık yoğunluk fonksiyonunu bulalım:
5
U = X cos θ + Y sin θ
V = X sin θ − Y cos θ
dönüşümü yapılır. U ve V nin ortak olasılık yoğunluk fonksiyonu,
1
− 2 (u 2 +v2 )
1
2σ
, −∞ < u, v < ∞
e
fU ,V (u , v) = 2πσ 2
0
,diğer hallerde
(2.3)
olur. U nun marjinal olasılık yoğunluk fonksiyonu,
1
− 2 u2
1
2σ
e
, −∞ < u < ∞
fU (u ) = 2πσ
0
,diğer hallerde
(2.4)
biçiminde elde edilir (Rao 1973).
2.1.2 Maxwell Tanımlaması
Moleküllerin hızları için aşağıdaki varsayımların sağlandığı düşünülsün:
a) Üç boyutlu ortogonal herhangi bir koordinat sistemine göre hız büyüklüğünün
bileşenleri u, v, w olsun. Bunların her biri bağımsızdır.
b) u, v, w’ nin marjinal dağılımları aynıdır.
c) Faz uzayı u, v, w bileşenlerine sahip moleküllerin yoğunluğu hızın yönüne değil
büyüklüğüne bağlıdır.
f
fonksiyonu, (u, v, w) hız bileşenlerinin olasılık yoğunluk fonksiyonu ve g
fonksiyonu, hızın olasılık yoğunluk fonksiyonu olsun,
g (v) = f (u ) f (v) f ( w) ,
fonksiyonel
denklemi
V 2 = u 2 + v 2 + w2
yazılır.
Bu
denklem
Herschel
tanımlamasındaki
ϕ ( x) + ϕ ( y ) = ϕ (r ) denklemine benzer. Bu denklem çözüldüğünde normal dağılımın
olasılık yoğunluk fonksiyonu ortaya çıkar (Rao 1973).
6
2.1.3 Hagen Tanımlaması
Hatalar için aşağıdaki varsayımları ele alalım:
a) Rasgele değişken olan belli bir hata, çok sayıda eşit büyüklükte, istenildiği kadar
küçük hata bileşenlerin toplamı olsun.
b) Hata bileşenleri bağımsızdır.
c) Her hata bileşeni için pozitif veya negatif olma olasılığı eşit olsun.
Her bir hata bileşeni, ±ε değerlerini
1
olasılığı ile alsın. Her bir hata bileşenlerinin
2
ortalaması 0 varyansı ε 2 dır. Hata bileşenleri toplamı
X = ε 1 + ε 2 + ... + ε n
ise beklenen değeri
E ( X ) = E (ε1 ) + E (ε 2 ) + ... + E (ε n ) = 0
varyansı
V ( X ) = V (ε1 ) + V (ε 2 ) + ... + V (ε n ) = nε 2 = σ 2
olur.
V ( X ) = nε 2 = σ 2 olacak şekilde, n → ∞ için ε i ’ in dağılımını bulmak için karakteristik
fonksiyonundan faydalanırız. ε i ’ in karakteristik fonksiyonu
n
n
M X (t ) = E (e ) = ∏ E (e
itX
i =1
itX i
t2
t4
1
) = (eitε + e − itε ) = 1 − ε 2 + ε 4 + ...
4!
2
2!
n
t σ
−
t2 σ 2
1
n →∞
= 1 −
+ d
→e 2
2 n
n
2
n
2
(2.5)
şeklinde oluşan bu karakteristik fonksiyon; ortalaması 0, varyansı σ 2 olan normal
dağılımın karakteristik fonksiyonudur (Rao 1973).
7
2.1.4 Olasılık yoğunluk fonksiyonu f olan bir dağılımın entropisi,
∞
H ( f ) = − ∫ f ( x) log f ( x)dx
−∞
şeklinde olan,
∞
∫
∞
∫
f ( x)dx = 1 ,
−∞
∞
xf ( x)dx = µ
−∞
,
∫ (x − µ)
2
f ( x)dx = σ 2
−∞
kısıtlaması altında, sürekli dağılımlar arasında entropisi maksimum olan dağılım,
1 x−µ
1
−
e 2 σ , −∞ < x < ∞
f ( x) = 2πσ
,diğer hallerde
0
2
(2.6)
şeklinde bir normal dağılım olarak ortaya çıkar (Rao 1973).
2.1.5 Matematiksel Tanımlama
Normal dağılımın olasılık yoğunluk fonksiyonunu elde etmek için diğer bir yöntem de
matematiksel tanımlamadır.
f ( x) = e− x
2
/2
ifadesini göz önüne alalım.
∞
I=
∫
∞
∫e
f ( x)dx =
−∞
− x2 / 2
dx
−∞
Bu integrali bu haliyle almak mümkün değildir. Ancak,
∞
I=
∫
∞
f ( y )dy =
−∞
∫e
− y2 / 2
dy
−∞
şeklinde ikinci bir tanımlama yapıldığında,
∞
∫e
−∞
−
x2
2
∞
dx =
∫e
−
y2
2
dy
−∞
dır. Bu durumda
8
∞
I =
2
∫e
−
x2
2
−∞
∞
dx. ∫ e
−
y2
2
∞ ∞
dy =
−∞
∫ ∫e
−
( x2 + y 2 )
2
∞ ∞
dxdy =
−∞ −∞
∫∫
f ( x, y )dxdy
(2.7)
−∞ −∞
şekline dönüşür. Buradan da kutupsal koordinatlar özelliklerine dayanarak,
y
r = x2 + y2
y
θ
x
x
Şekil 2.1. Kutupsal koordinatların grafikle gösterilişi
x = r cos θ ve y = r sin θ dönüşümü altında (2.7)’yi
∫∫ f ( x, y )dxdy = ∫∫ f (r cos θ , r sin θ )rdrdθ
R
şeklinde ifade ederiz.
G
Buradan da, x = g (u , v) ve y = h(u , v) Jacobian dönüşümü yardımıyla
∫∫ f ( x, y )dxdy = ∫∫ f ( g (u, v)h(u, v)) J (u, v) dudv
R
G
elde edilir.
∂x
∂ ( x, y ) ∂u
J (u , v) =
=
∂y
∂ (u , v)
∂u
∂x
∂r
J (r , θ ) =
∂y
∂r
∂x
∂v ∂x ∂y ∂y ∂x
= . − .
∂y ∂u ∂v ∂u ∂v
∂v
∂x
cos θ
∂θ
=
∂y
sin θ
∂θ
− r sin θ
r cos θ
= r (cos 2 θ + sin 2 θ ) = r
bulunur. (2.8) denklemini kullanarak
9
(2.8)
∫∫ f ( x, y )dxdy = ∫∫ f (r cos θ , r sin θ ) r drdθ = ∫∫ f (r cos θ , r sin θ )rdrdθ
R
G
G
elde edilir (Thomas and Finney 1998).
2π ∞
I =
2
∫ ∫e
−
r2
2
2π
rdrdθ =
0 0
∫ dθ = 2π
0
Ayrıca
∞
Ι2 =
∫e
− x2 / 2
dx = 2π
ise Ι = 2π
−∞
dır. Dolayısıyla
1
2π
∞
−x /2
∫ e dx = 1 ve
2
−∞
1
2π
∞
∫e
− y2 / 2
dy = 1
(2.9)
−∞
elde edilir.
İntegrale yeni değişken girersek y =
x−a
, b>0
b
∞
( x − a)2
1
exp
−
dx = 1
∫
2b 2
−∞ b 2π
f ( x) =
( x − a)2
1
exp −
,
2b2
b 2π
−∞ < x < ∞
(2.10)
Bu ifadede a yerine µ ve b yerine σ yazıldığında,
1
( x − µ )2
exp
−
,
f ( x) = σ 2π
2σ 2
0
,
−∞ < x < ∞
diğer hallerde
normal olasılık yoğunluk fonksiyonu elde edilir (Hogg and Craig 1995).
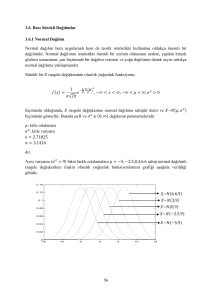
2.2 Normal Dağılımın Özellikleri
1 x−µ
σ
−
1
Olasılık yoğunluk fonksiyonu f ( x) =
e 2
2πσ
2
olan normal dağılımda;
a) Her µ için f ( µ + x) = f ( µ − x) olduğundan, fonksiyonun eğrisi x = µ ’ye göre
simetriktir. Aritmetik ortalama, mod ve medyan birbirine eşittir.
10
b) Dağılımın çarpıklık ölçüsü α 3 = 0 ve basıklık ölçüsü α 4 = 3 ’tür (Chiang 2003).
c) Dağılım x = µ değerinde bir maksimuma sahiptir (Chiang 2003).
d) Normal dağılım µ ve σ 2 olmak üzere iki parametreye sahiptir (Chiang 2003).
e)
f(x)
µ
x
Şekil 2.2. Normal Olasılık Yoğunluk Fonksiyonu Grafiği
Grafikte x = µ aşağı konkavdır.
Asimptotik olarak x → ±∞ iken f ( x) → 0 dır. Bütün x için f ( x) ≥ 0 olduğu için x’in
pozitif veya negatif bütün değerlerinde f grafiği yukarı konkavdır. Konkavlık
değişimi
olan bu noktaya büküm noktası denir ve f ′′( x) = 0 denklemi çözülerek bulunur.
x = µ ± σ ‘da oluşan büküm noktasını buluruz (Meyer 1970).
2.3 Normal Dağılım İçin Uygunluk Testleri
Veriler her zaman normal dağılıma uygun olmayabilir. Gözlenen her veri kümesi için
normal dağılıma uygun olduğunu varsayarak istediğimiz istatistiksel sonuçları elde
etmeye çalışırsak uygulamada yanıltıcı ve çelişkili durumlarla karşılaşılır. Bu amaçla
hata yapmamak ve bilinçli olmak için bir veri kümesinin hangi dağılıma uygun
olduğunu bilmek gerekir. Biz normal dağılımla ilgileneceğimiz için verilerin normal
dağılıma uygun olup olmadığını bilmemiz gerekmektedir. Bunun için aşağıdaki normal
dağılıma uygunluk testleri incelenecektir. Bu testler şunlardır:
11
1. Q-Q Nokta grafik yöntemi
2. Çeyreklikler arası fark yöntemiyle oluşan test
3. Ki-kare uygunluk testi
4. Kolmogorov-Simirnov uygunluk testi
5. Lilliefors normallik testi
6. Shapiro-Wilk normallik testi
7. İki ve daha fazla değişken için normallik testleri
2.3.1 Q-Q Nokta Grafik Yöntemi
Q-Q nokta grafik yöntemi, bir veri kümesinin normal dağılıma uygunluğunu belirleyen
yöntemlerden birisidir. Grafikteki noktalar, bir doğru etrafında kümelenmemişler ise
normallik varsayımının sağlanmadığı görülür. Normallikten ayrılışlar olduğunda
dönüşüm yapılarak dağılımın normal dağılım göstermesi sağlanabilir. Eğer gözlem
sayısı n ≥ 20 ise Q-Q nokta grafik yöntemi iyi sonuç vermektedir. Bu yöntem aşağıdaki
aşamalarda yapılır.
a) Bir veri kümesindeki gözlemler küçükten büyüğe doğru sıralanır.
b) Her bir gözleme ilişkin sırasıyla
pi =
i − .5
(i − 1/ 2)
veya pi =
n
n
n≠0
yüzdeliği hesaplanır. Burada i gözlem değeri, n gözlem sayısıdır.
c) pi yüzdeliğine karşılık gelen standart normal değerler z tablosundan bulunur.
d) Gözlem değerleri ( xi ), yüzdelik değerleri pi ’ye karşılık gelen zi değerleri ( xi , zi )
çiftleri için nokta grafiği çizilir ve nokta dağılımının bir doğru üzerinde olup olmadığına
bakılır. Grafikteki nokta dağılımı bir doğru üzerinde ise verilerin normal dağılım olduğu
görülmektedir (Johnson and Wichern 1992).
12
2.3.2 Çeyreklikler Arası Fark Yardımıyla Oluşan Test
Bir veri kümesinde çeyreklikler arası farkı standart sapmaya oranlanarak normallik testi
uygulanır. Önce birinci ve üçüncü çeyreği hesaplarız. Birinci çeyreği bulmak için önce
verileri küçükten büyüğe sıralarız. Oluşturulan seride
1
( n + 1) ’nci sıraya karşılık gelen
4
değer birinci çeyrek veya 25. yüzdelik diye adlandırılır, QL şeklinde gösterilir. Aynı
şekilde üçüncü çeyreği bulmak için de verileri küçükten büyüğe sıralarız. Oluşturulan
seride
3
( n + 1) ’nci sıraya karşılık gelen değer üçüncü çeyrek veya 75. yüzdelik diye
4
adlandırılır, QU şeklinde gösterilir. Çeyreklikler arası fark ile standart sapma arasındaki
oran hesaplanır. Bu oran IQR / s şeklinde gösterilir. Burada s değeri standart sapmadır.
IQR = QU − QL olduğuna göre, IQR / s ≅ 1,3 ise normal dağılıma yakınsama meydana
gelir (Sincich 1996).
2.3.3 Ki-Kare Uygunluk Testi
Ki-Kare testi rasgele değişkenlerin olasılık dağılımlarının hipotez testlerinde kullanılır.
Bir veri kümesinin normal dağılıma uygun olup olmadığını belirlemek için kullanılan
testlerden biridir. Ki-kare testi, herhangi bir durumda hipotezi kabul etmek veya
reddetmek için sağlanır. Bilinmeyen parametreleri tahmin etmek için gözlemlenen
değerler kullanılır. Parametrelerin tahmini gerçekleşirse beklenen frekanslar tanımlanır.
H 0 : F ( x) = F0 ( x) (Dağılıma Normal olasılık yoğunluk fonksiyonu uygundur).
H1 : F ( x) ≠ F0 ( x) ( Dağılıma Normal olasılık yoğunluk fonksiyonu uygun değildir).
biçimindeki hipotezler test edilir.
Ki-kare test istatistiği:
13
r
χ2 = ∑
i =1
( g i − ti ) 2
ti
(2.11)
formülünden elde edilmektedir.
Burada;
gi : i. sınıfta gözlenen birim sayısı (gözlenen frekanslar)
ti : i. sınıfta beklenen birim sayısı (teorik frekanslar)
r : Sınıf sayısı
olmaktadır.
Test istatistiği H 0 kabul edilirse r-1-k serbestlik dereceli ki-kare dağılımına sahiptir.
Burada k tahmin edilen parametre sayısıdır (Chiang 2003).
(2.11)’de hesaplanan test değeri α anlam düzeyinde ve r-1-k serbestlik dereceli ki-kare
tablo değerinden küçükse veriler normal dağılıma uygundur.
2.3.4
Kolmogorow-Simirnov Uygunluk Testi
Kolmogorow-Smirnov uygunluk testi bir veri kümesinin normalliğinin belirlenmesinde
kullanılan testlerden birisidir. Hipotez testi aşağıdaki biçimde kurulur.
H 0 : F ( x) = F0 ( x) ( Bütün x 'ler için )
H1 : F ( x) ≠ F0 ( x) ( En az bir x için)
Teorik birikimli dağılım fonksiyonu ile gözlenen birikimli dağılım fonksiyonu arasında
ilişki olup olmadığını ortaya koymak amacıyla; söz konusu dağılım fonksiyonları
karşılaştırılarak, dağılımlar arasındaki en büyük mutlak farkın test istatistiği oluşturulur.
Kolmogorow-Smirnov Uygunluk testinin test istatistiği;
sup F0 ( x) − S n ( x)
(2.12)
−∞< x <∞
formülünden elde edilmektedir.
14
Büyük örneklem için,
n sup F0 ( x) − S n ( x) ’in limit dağılımından elde edilen kritik
değerler 1948 yılında Smirnov tarafından tablolanmıştır (Lehmann 1986).
Elde edilen test istatistiğinin belirli bir örneklem büyüklüğü ve seçilen anlamlılık
düzeyindeki Kolmogorow-Smirnov tablo değerinden büyük olması durumunda H 0
reddedilmekle ve dağılımın normal olmadığı sonucuna ulaşılmaktadır.
Kolmogorov Simirnov uygunluk testinin Ki-kare uygunluk testine göre iki önemli
üstünlüğe sahip olduğu ileri sürülmektedir. Bu üstünlükler şunlardır:
a) Küçük mevcutlu örneklemlerde Kolmogorov-Simirnov testi daha güvenilir
sonuçlar verir.
b) Herhangi bir örneklem büyüklüğü için bu test çoğu zaman Ki-kare testinden
daha güçlü sonuçlar vermektedir (Lilliefors 1967).
2.3.5
Lilliefors Normallik Testi
Parametreler bilinmediğinde Lilliefors testini kullanmak gerekir. Bilinmeyen dağılım
fonksiyonu F(x)'den elde edilen X 1 , X 2 ,..., X n biçimindeki n hacimlik rasgele bir
örneklemin ortalaması ( X ) ve standart sapması S > 0 ise,
Zi =
Xi − X
S
(2.13)
değerlerini hesaplamak mümkündür. Elde edilen bu değerler gözlenen birikimli dağılım
fonksiyonunu oluşturmaktadır. Lilliefors testinin hipotezleri ise;
H 0 : Rasgele örneklem, ortalaması ve varyansı belirli olmayan bir normal dağılımdan
çekilmiştir.
H1 : X i ' lerin çekildiği dağılım fonksiyonu normal değildir.
şeklinde tanımlanabilir.
15
Yukarıdaki biçimde oluşturulmuş hipotezlerin testi için kullanılan Lilliefors test
istatistiği yine; (2.12)’de verilen
sup F0 ( x) − S n ( x)
−∞< x <∞
formülünden elde edilmektedir. Formüldeki kuramsal birikimli dağılım fonksiyonu
F0 ( x) ile gözlenen birikimli dağılım fonksiyonu S n ( x) arasındaki mutlak farkların en
büyüğü test istatistiğinin değerini oluşturmaktadır. Bu değer Lilliefors tablo değerinden
büyük bulunduğunda
X i ’lerin dağılım fonksiyonun normal olmadığı sonucuna
ulaşılmaktadır (Conower 1980).
2.3.6
Shapiro-Wilk Normallik Testi
Shapiro-Wilk testinde, dağılımı bilinmeyen bir fonksiyon olan F ( x) 'den çekilen
X 1 , X 2 ,..., X n
değerlerinden
oluşan
n
hacimlik
bir
örneklemin
verilerinden
yararlanılmaktadır. Shapiro-Wilk testi ile ilgili hipotezler ;
H 0 : F ( x) , ortalama ve varyansı belirli olmayan bir normal dağılıma sahiptir.
H1 : F ( x) ' in dağılımı normal değildir.
biçiminde oluşturulmaktadır.
Oluşturulan bu hipotezleri test etmek amacıyla,
2
n
∑ ai ( X (i ) )
W = in=1
∑ ( X i − X )2
(2.14)
i =1
biçimindeki Shapiro-Wilk test istatistiğine ulaşılmaktadır (Pearson and Hartley 1972).
Burada a değerine ise a′ = (a1 , a2 ,..., an ) = mV −1[m′V −1V −1m]−1/ 2 şeklinde ulaşılmaktadır.
16
m′ = (m1 , m2 ,..., mn ) ifadesi standart normal sıra istatistiklerinin beklenen değeridir.
V : (nxn) boyutlu kovaryans matrisidir.
X ′ = ( X 1 , X 2 ,..., X n ) rasgele örneklemdir.
Daha sonra örneklem verileri X (1) ≤ X (2) ≤ ... ≤ X ( n ) biçiminde sıralanmaktadır.
(2.14)’deki formülden elde edilen test istatistiği ve örneklem hacminden hareketle
Shapiro - Wilk tablosundan bulunan değer , seçilen anlamlılık düzeyinden büyük
olduğunda dağılımın normal olduğu sonucuna ulaşılmaktadır.
Normallik testlerinin güçleri arasında karşılaştırma yapıldığında Shapiro-Wilk testinin
en güçlü oduğu ileri sürülmektedir (Shapiro et al 1968).
2.3.7 İki ve Daha Fazla Değişken İçin Normallik Testleri
İki ve ikiden çok değişkenli dağılımlarda, sıralanmış uzaklıklar olan d i2 (i = 1,2,...,n) ile
χ 2 p;(i −0,5) / n değerlerine ilişkin nokta grafiğinin düz bir çizgi oluşturması durumunda
değişkenlerin yaklaşık olarak çok değişkenli normal dağıldığı görülür.
Sırasıyla
1 − 1/ 2 2 2 − 1/ 2
2 n − 1/ 2
, χp
,…, χ p
n
n
n
χ p2
değerlerine
karşılık
gelen
2
2
d (1)
≤ d (2)
≤ ... ≤ d (2n ) aralıklarının karesi grafikte düz bir çizgi oluşturursa veriler normal
dağılmaktadır (Johnson and Wichern 1992).
2.4 Beklenen Değer
X rasgele değişkenin olasılık yoğunluk fonksiyonu f ( x) olmak üzere, beklenen değeri;
1) Eğer X rasgele değişkeni kesikli ise
17
E ( X ) = ∑ xi P( X = xi ) =
x
∑ xf ( x)
(2.15)
x
2) X rasgele değişkeni sürekli ise
∞
E(X) =
∫ x f ( x)dx
(2.16)
−∞
ile ifade edilir. Burada E(X)’in var olabilmesi için E(X)’in mutlak yakınsak olması
şarttır. Yani E ( X ) < ∞ dir (Meyer 1970).
2.5 Varyans
X rasgele değişkeni için E ( X − EX ) 2 beklenen değerine bu rasgele değişkenin varyansı
denir.
Kesikli durumda varyans
σ 2 = E ( X − µ ) 2 = ∑ ( x − µ ) 2 f ( x)
(2.17)
x
dir. Sürekli durumda ise,
∞
σ 2 = E ( X − µ ) 2 = ∫ ( x − µ )2 f ( x)dx = E ( X 2 ) − µ 2
(2.18)
−∞
olarak belirlenir.
2.6 Moment Çıkaran Fonksiyon
X rasgele değişkeninin moment çıkaran fonksiyonu M X (t ) ile gösterilip t’nin bütün
gerçel değerleri için
M X (t ) = E (etX )
ile tanımlanır.
X rasgele değişkeni kesikli ise M X (t ) = E (etX ) = ∑ etx f ( x)
(2.19)
x
∞
X rasgele değişkeni sürekli ise M X (t ) = E (etX ) =
∫e
tx
f ( x)dx
(2.20)
−∞
olarak bulunur. Normal olasılık yoğunluk fonksiyonun moment çıkaran fonksiyonu ise
18
M X (t ) = e
1
2
µ t + σ 2t 2
şeklinde bulunur.
2.7 Normal Dağılım İçin Bazı Önemli Teoremler
Teorem 2.1 X 1 , X 2 ,..., X n bağımsız rasgele değişkenleri N ( µ1 , σ 21 ) , N ( µ 2 , σ 2 2 ) , ... ,
N ( µ n , σ 2 n ) normal dağılsın.
Y=k1 X 1 + k2 X 2 + ... + kn X n
rasgele değişkeninin k1, k2, ..., kn reel sabitlerle dağılımı
ortalaması k1µ1 + k2 µ 2 + ... + kn µ n ve varyansı k12σ 21 + k22σ 2 2 + ... + kn2σ n n olan normal
dağılıma sahip olur ve
n
n
i =1
i =1
N (∑ ki µi , ∑ k 2iσ 2 i )
(2.21)
biçiminde elde edilir.
İspat 2.1 X 1 , X 2 ,..., X n rasgele değişkenleri bağımsız oldukları için Y’nin moment
çıkaran fonksiyonu
M Y (t)=E ( exp[t(k1 X 1 + k2 X 2 + ... + kn X n )]) = E (etk1 X1 ) E (etk2 X 2 )...E (etkn X n )
σ 2t 2
E (etX i ) = exp µi t + i bütün t, i =1,2,...,n için.
2
σ i 2 ( ki t ) 2
tki X i
E (e ) = exp µi (ki t ) +
2
Y’nin moment çıkaran fonksiyonu
n
(
ki2σ i2 )t 2
∑
2 2 2
n
n
(k σ )t
i =1
M Y (t ) = ∏ exp (ki µi )t + i i
= exp (∑ ki µi )t +
2
2
i =1
i =1
n
n
i =1
i =1
N (∑ ki µi , ∑ k 2iσ 2 i )
dır.
19
Teorem 2.2 X 1 , X 2 ,..., X n bağımsız rasgele değişkenler M X i (t ) , i =1,2,3,...,n moment
n
Y = ∑ ai X i
çıkaran fonksiyonları ile gösterilirse,
ifadesinin moment çıkaran
i =1
fonksiyonu
n
M Y (t ) = ∏ M X i (ait )
(2.22)
i =1
şeklinde olur. Burada a1 , a 2 ,..., an reel sabitlerdir (Hogg and Craig 1995).
İspat 2.2 Y’nin moment çıkaran fonksiyonu
M Y (t ) = E etY = E et ( a1 X1 + a2 X 2 +...+ an X n ) = E e a1tX1 e a2tX 2 ...e antX n = E e a1tX1 E e a2tX 2 ...E e antX n
dır. Burada X 1 , X 2 ,..., X n bağımsızdır. Bununla birlikte,
E etXi = M X i (t ) olduğu için
E eaitXi = M X i (ai t )
dır. Böylece
M Y (t ) = M 1 (a1t ) M 2 (a2t )...M n (ant ) =
n
∏ M (a t )
i
i
(2.23)
i =1
Bu da Teorem 2.1’in genelleştirilmiş halidir.
Teorem 2.3 Farz edelim ki X 1 , X 2 ,..., X n rasgele örnekleminin moment çıkaran
fonksiyonu aşağıdaki şekillerde ifade edilebilir:
n
a) Y = ∑ X i ’nin moment çıkaran fonksiyonu
i =1
n
M Y (t ) = ∏ M (t ) = [ M (t )]
n
(2.24)
i =1
n
b) X = ∑ X i / n ’nin moment çıkaran fonksiyonu
i =1
t t
M X (t ) = ∏ M = M
n n
i =1
n
n
(2.25)
dir .
20
Teorem 2.4 X ve Y olarak ifade edilen iki rasgele değişkenin moment çıkaran
fonksiyonları sırasıyla M X (t ) ve M Y (t ) olsun. Bütün t değerleri için M X (t ) = M Y (t )
ise X ve Y aynı dağılıma sahiptir.
Teorem 2.5 X ve Y bağımsız rasgele değişkenleri için Z = X+Y olsun. X, Y ve Z
rasgele değişkelerin moment çıkaran fonksiyonları M X (t ) , M Y (t ) ve M Z (t ) ise
M Z (t ) = M X (t ) M Y (t )
dır.
İspat 2.5 M Z (t ) = E (e Zt ) = E e( X +Y ) t = E (e Xt .eYt ) = E (e Xt ) E (eYt )
= M X (t ) M Y (t )
(2.26)
Ayrıca X 1 , X 2 ,..., X n bağımsız değişkenlerin moment çıkaran fonksiyonu M X i ,
i =1,2,...,n ise o zaman Z = X 1 + X 2 + ... + X n ’in moment çıkaran fonksiyonu M Z ’dir.
M Z (t ) = M X1 (t ) M X 2 (t )...M X n (t )
(2.27)
Teorem 2.6 X 1 , X 2 ,..., X n bağımsız rasgele değişkenleri N ( µ i , σ i2 ) , i =1,2,...,n şeklinde
normal dağılmış ise Z = X 1 + X 2 + ... + X n ‘in dağılımı
n
n
N ∑ µ i , ∑ σ i2
i =1
i =1
(2.28)
olur. Bununla birlikte,
X 1 , X 2 ,..., X n rasgele değişkenleri N ( µ , σ 2 ) dağılmışlarsa
1) X ve X i − X terimleri bağımsızdırlar (i =1,2,…,n).
2) X ve S2 bağımsızdır.
3) nS 2 / σ 2 , (n-1) serbestlik dereceli ki-kare dağılır. Yani χ 2 ( n −1) dir.
21
2.8 Yakınsama Teoremleri
Yakınsama teoremleri ile gözlemlenen bir rasgele değişkenin normal dağılıma
yakınsaması incelenecektir.
Teorem (Lapunov) 2.7 X 1 , X 2 ,..., X n bağımsız rasgele değişkenlerinin ortalaması µ ,
varyansı σ 2 ve üçüncü derece momenti M 3 = E X i − µ
σ ( n ) = σ 12 + σ 22 + ... + σ n2
lim
n →∞
M (n)
σ
1
2π
ise
M ( n ) = µ13 + µ 23 + ... + µ n3 olsun.
= 0 ilişkisi varsa, Z =
(n)
3
X 1 + X 2 + ... + X n − µ1 − µ 2 − ... − µ n
σ (n)
rasgele değişkeni
x
∫e
−t 2 / 2
dt
(2.29)
−∞
dağılım fonksiyonu ile standart normal dağılıma yakınsar (Zubrzycki 1970).
Teorem (Lindeberg-Feller) 2.8 X 1 , X 2 ,..., X n değişkenleri FX ( x) dağılımlı ve
E ( X i ) = µi ortalamalı, V ( X i ) = σ i2 varyanslı bağımsız rasgele değişkenler olsun.
n
Z=
∑(X
i
− µ)
i =1
Cn
1/ 2
n
Cn = ∑ σ i2
i =1
olarak tanımlanır. Her ε > 0 için
lim
n →∞
1
Cn2
n
∑∫
i =1
lim max
n→∞
1≤ i ≤ n
x
F ( x) =
∫
−∞
σi
Cn
x − µi >ε Cn
( x − µi ) 2 dFi ( x) = 0 olursa bu ilişki
=0
1 −t2 / 2
e
dt
2π
(2.30)
dağılımı ile ortalaması 0 ve varyansı 1 olan standart normal dağılıma yaklaşır.
22
2.9 İki Değişkenli Normal Dağılım
İki değişkenli rasgele değişkenler X = ( X 1 , X 2 )′ olsun. Bunların beklenen değeri ve
kovaryansı sırayla
µ1
E[X ] = µ =
µ2
ve
σ ii = σ i2
σ ij
σ 12
σ
Cov [ X 1 , X 2 ] = ∑ = 11
,
σ 21 σ 22
i=j
i≠ j
olup det ∑ = σ 12σ 22 − σ 122 ≠ 0 olacağından öyle σ 12 = ρ12σ 1σ 2 eşitliğini kullanarak
∑ −1 =
σ 22
σ 11σ 22 − σ 122 −σ 12
1
−σ 12
σ 22
1
=
σ 11 σ 11σ 22 (1 − ρ122 ) − ρ12σ 1σ 2
− ρ12σ 1σ 2
σ 11
elde edilir. O halde iki değişkenli normal olasılık yoğunluk fonksiyonu
( x − µ )′ ∑ −1 ( x − µ ) = ( x1 − µ1
x2 − µ2 )
σ 22
1
2
σ 11σ 22 (1 − ρ12 ) − ρ12σ 1σ 2
− ρ12σ 1σ 2 x1 − µ1
σ 11
x2 − µ2
σ 22 ( x1 − µ1 ) 2 + σ 11 ( x2 − µ 2 ) 2 − 2 ρ12σ 1σ 2 ( x1 − µ1 )( x2 − µ2 )
=
σ 11σ 22 (1 − ρ122 )
x − µ 2 x − µ 2
x1 − µ1 x2 − µ 2
1
1
1
2
2
+
−
=
2
ρ
12
σ
σ
(1 − ρ122 ) σ 1 σ 2
1
2
şeklinde elde edilir. Buna göre iki değişkenli normal olasılık yoğunluk fonksiyonu
(2.31)’deki gibi tanımlanır.
f ( x1 , x2 ; µ , ∑) =
1
− ( x − µ ) ′ ∑ −1 ( x − µ )
1
e 2
2π det(∑)
yani
f ( x1 , x2 ) =
e
x − µ 2 x − µ 2
x − µ x − µ
1
1 1 + 2 2 − 2 ρ12 1 1 2 2
−
2
2(1− ρ12 ) σ 1 σ 2
σ1 σ 2
(2.31)
2πσ 1σ 2 1 − ρ
2
12
dir (Johnson and Wichern 1992).
23
İki değişkenli normal olasılık yoğunluk fonksiyonu f ( x1 , x2 ) ’in özellikleri şunlardır.
1) f ( x1 , x2 ) birleşik olasılık yoğunluk fonksiyonudur.
2) X 1 değişkeni N ( µ1 ,σ 11 ) ve X 2 değişkeni N ( µ 2 , σ 22 ) olarak normal dağılır.
3) ρ değeri ise X 1 ve X 2 rasgele değişkenlerinin korelasyon katsayısı olup
ρ=
cov( X 1 , X 2 )
σ
= 12
V ( X 1 )V ( X 2 ) σ 1σ 2
(2.32)
ile hesaplanır ve −1 ≤ ρ ≤ 1 aralığında bir değerdir.
İki değişkenli normal dağılım µ1 , µ2 , σ 1 , σ 2 ve ρ12 olmak üzere beş parametreye
sahiptir (Hogg and Craig 1995).
Marjinal dağılımlar ise sırasıyla aşağıda gösterilmiştir. Bunlar,
∞
f ( x1 ) =
∫
f ( x1 , x2 )dx2 =
−∞
2
1
e − ( x1 − µ1 ) /(2σ11 )
σ 1 2π
(2.33)
ve
∞
f ( x2 ) =
∫
−∞
f ( x1 , x2 )dx1 =
1
σ 2 2π
e− ( x2 − µ2 )
2
/(2σ 22 )
(2.34)
şeklindedir. İki değişkenli normal dağılımda;
( X 1 , X 2 ) ~ BVN ( µ1 , µ 2 ,σ 11 , σ 22 , ρ12 ) ise
1) X 1 = x1 verildiğinde X 2 ’nin koşullu dağılımı
σ
X 2 x1 ~ N µ 2 + ρ12 2 ( x1 − µ1 ), σ 22 (1 − ρ122 )
σ1
2) X 2 = x2 verildiğinde X 1 ’in koşullu dağılımı
σ
X 1 x2 ~ N µ1 + ρ12 1 ( x2 − µ 2 ), σ 11 (1 − ρ122 )
σ2
şeklindedir (Bain and Engelhardt 1989).
İki değişkenli normal olasılık yoğunluk fonksiyonunun moment çıkaran fonksiyonu
σ 11t12 + 2 ρ12σ 1σ 2t1t2 + σ 22t22
M X (t1 , t2 ) = exp µ1t1 + µ 2t2 +
2
şeklinde tanımlanır (Hogg and Craig 1995).
24
(2.35)
2.10 Çok Değişkenli Normal Dağılım
Burada çok değişkenli normal dağılım fonksiyonun tanımı, özellikleri ve elde edilecek
önemli sonuçlar incelenecektir.
Tanım 2.1 Bir X vektörü Normal dağılıma sahipse, olasılık yoğunluk fonksiyonu, ∑
pozitif tanımlı bir matris olmak üzere
1
−1
exp − 2 ( x − µ )′ ∑ ( x − µ )
, x∈ Rp,µ ∈ Rp
p
1
f X ( x) =
(2π ) 2 (det(∑)) 2
0
,diğer hallerde
(2.36)
şeklindedir. Buna göre,
∫∫ ...∫ f
X
( x)dx1dx2 ..dx p = 1
Rp
eşitliği görülebilir.
Bu tanıma William C. Horrace tarafından tanımlanan tanımı da ilave olarak verilebilir.
′
Tanım 2.2 Farz edelim ki X * = x1* , x2* ,..., x*p , p ≥ 2 ile p boyutlu rasgele
değişkenler olsunlar. Olasılık yoğunluk fonksiyonu
1
−
1
f X * ( x, µ , ∑) = (2π ) − p / 2 (det ∑) 2 exp − ( x − µ )′ ∑ −1 ( x − µ ) ; x ∈ R p
2
(2.37)
ise X * değişkeni µ ′ = µ1 , µ 2 ,..., µ p ortalama vektörlü ve ( pxp ) boyutlu pozitif
tanımlı tekil olmayan korelasyon matrisli n değişkenli normal dağılıma sahiptir.
Standart notasyon olarak X * ~ N p ( µ , ∑ ) ifadesini kullanacağız.
c = c1 , c2 ,..., c p ∈ R p altında X * in X ′ = x1 , x2 ,..., x p truncated hali şu şekilde
ifade edilir.
25
1
(2π )− p / 2 (det ∑) −1/ 2 exp − ( x − µ )′ ∑ −1 ( x − µ )
2
;x∈Rp ;
f X ( x, µ , ∑, c ) =
≥c
∞
1
−p/2
−1/ 2
−1
(2π )
(det ∑) ∫ e xp − ( x − µ )′ ∑ ( x − µ ) dx
2
c
1
exp − ( x − µ )′ ∑ −1 ( x − µ )
2
;x∈Rp ,
= ∞
≥c
1
−1
∫c e xp − 2 ( x − µ )′ ∑ ( x − µ ) dx
(2.38)
∞
Burada
{
∫
integrali
c
p
boyutlu
c’den
∞ ’a
bir
Riemann
integralidir
ve
}
R≥pc = x ∈ R p : x ≥ c dir.
X * nın her elemanı için c altında truncated ile ilgilenilir. Bununla birlikte X * nın alt
kümeleri de truncated olur. Bu da X *j için limit −∞ dan c j ’e gider. Örneğin eliptik
p
truncated. Burada X
*
ifadesi
∑a
tj
X *j > atj biçiminden truncatedi dikkate alınırken
j =1
a < X *′ ∑ −1 X * < b şartı ile sınırlandırılır.
Sonuçta, ( X 1* , X 2* ) çiftinden truncated dikkate alırız, dağılımın spesifik bölümü
p
belirtilir ve
∑ x E( X
j
*
j
) olarak maksimize edilir. Aşağıda izleyeceğimiz tanımlama
j =1
yararlıdır.
M = c − µ , t ∈ R p ve X j sembolik elemanı ile P = c − µ − i ∑ t ifade edilirse,
( px1)
( px1)
sırasıyla t j , Pj ; j ∈ N , N = [1, 2,..., p ] ve i = −1 dir (Horrace 2004).
2.10.1 Çok Değişkenli Normal Dağılımın Beklenen Değeri ve Kovaryansı
X = X 1 , X 2 ,..., X p rasgele vektörünün beklenen değeri
26
E ( X 1 ) µ1
E( X ) µ
2 2
µ = E( X ) =
=
M M
E ( X p ) µ p
(2.39)
şeklinde tanımlanmış olup, kovaryansı ise
X 1 − µ1
X 2 − µ 2
′
X − µ1 , X 2 − µ 2 ,..., X p − µ p
∑ = E ( X − µ )( X − µ ) = E
M
1
X p − µp
2
( X 1 − µ1 )
( X 1 − µ1 )( X 2 − µ2 ) K ( X 1 − µ1 ) ( X p − µ p )
2
( X − µ )( X − µ )
K ( X 2 − µ2 ) ( X p − µ p )
( X 2 − µ2 )
2
2
1
1
=E
M
M
K
M
2
( X p − µ p ) ( X 1 − µ1 ) ( X p − µ p ) ( X 2 − µ 2 ) K
µ
−
X
(
)
p
p
2
E ( X 1 − µ1 )
E ( X 1 − µ1 )( X 2 − µ2 )
2
E ( X − µ )( X − µ )
E ( X 2 − µ2 )
2
2
1
1
=
M
M
E ( X p − µ p ) ( X 1 − µ1 ) E ( X p − µ p ) ( X 2 − µ 2 )
cov( X 1, X 2 )
V ( X1)
cov( X X )
V (X2)
2, 1
=
...
...
cov( X p , X 1 ) cov( X p , X 2 )
E ( X 1 − µ1 ) ( X p − µ p )
K E ( X 2 − µ2 ) ( X p − µ p )
K
M
2
K
E ( X p − µp )
K
... cov( X 1 , X p )
... cov( X 2 , X p )
=
...
...
...
V ( X p )
σ 11 σ 12
σ
21 σ 22
...
...
σ p1 σ p 2
... σ 1 p
... σ 2 p
(2.40)
... ...
... σ pp
şeklinde tanımlanır (Johnson and Wichern 1992).
2.10.2 Çok Değişkenli Normal Dağılımdan Çıkarılacak Bazı Sonuçlar
Sonuç 2.1 Bir ∑ matrisi tanımlanmışsa ∑ −1 de tanımlanabilir.
27
Eğer e vektörü ∑ ’nın λ öz değerine karşılık gelen öz birim vektörü ve ∑ ’nin tersi var
ise, o zaman e vektörü, ∑ −1 ’in
1
λ
öz değerine karşılık öz vektörüdür.
1
∑ e = λ e ise ∑ −1 e = e olarak ifade edilir.
λ
1
O halde, (λ , e) , ∑ için, , e de ∑ −1 için öz değer-öz vektör çiftidir. ∑ −1 de pozitif
λ
tanımlıdır. Bu da aşağıdaki gibi ifade edilir.
∑ pozitif tanımlı ve e ≠ 0 için bir öz vektör, O halde,
0 < e′ ∑ e = e′(∑ e) = e′(λ e) = λ e′e = λ
nx1 boyutlu herhangi bir x vektörü için,
p 1
x′ ∑ −1 x = x′ ∑
i =1 λi
p
′
1
2
e
e
x
=
i i
( x′ei ) ≥ 0
∑
i =1 λi
olduğu için λi−1 ( x′ei ) 2 her bir terimi pozitiftir. Yalnız x = 0 ise bütün i için x′ei = 0 dır.
p
1
∑ λ ( x′e )
i =1
i
i
2
> 0 ve ∑ −1 pozitif tanımlıdır.
Özetle, n boyutlu normal olasılık yoğunluk fonksiyonu
( x − µ )′ ∑ −1 ( x − µ ) = c 2
(2.41)
olacak şekilde bir elips tanımlar.
Bu elipsin merkezi µ ve eksenleri ise m c λi ei dir (i =1,2,...,p).
Burada ∑ ei = λi ei ’dir (Johnson and Wichern 1992).
Sonuç 2.2 X ~ N p ( µ , ∑) ise,
a11 X 1 + a12 X 2 + ... + a1 p X p
a21 X 1 + a22 X 2 + ... + a2 p X p
.
A X =
( qxp ) ( px1)
.
.
aq1 X 1 + aq 2 X 2 + ... + aqp X p
28
şeklindeki q bileşimleri N q ( Aµ , A ∑ A′) dağılır.
Yine, X + d ifadesi
( px1)
( px1)
N p ( µ + d , ∑)
(2.42)
dağılır. Burada d sabit vektördür.
Sonuç 2.3 X’ in bütün alt kümeleri normal dağılır. X ’i, X 1 ve X 2 olarak iki parçaya
ayırırsak, onların ortalama vektörü µ ve kovaryans matrisi ∑ olmak olsun.
X1
( qx1)
X = K
( px1)
X2
(( p − q ) x1)
µ1
( qx1)
µ = ...
( px1)
µ2
(( p − q ) x1)
M
∑11
( pxq )
∑ = L
M
( pxp )
M
∑ 21
(( p − q ) xq )
∑
L
∑ 22
(( p − q ) x ( p − q ))
12
( qx ( p − q ))
X 1 ~ N q ( µ1 , ∑11 )
(2.43)
dağılımına sahiptir (Johnson and Wichern 1992).
Sonuç 2.4 a) X 1 ve X 2 bağımsız ise Cov( X 1 , X 2 ) = 0 dır.
(2.44)
q1 xq2 sıfır matrisidir.
µ1 ∑11 M ∑12
X1
b) L ~ N q1 + q2 L , L M L
µ ∑
X 2
2 21 M ∑ 22
ise yalnız ∑12 = 0 olduğunda X 1 ve X 2 bağımsızdır.
c) X 1 ve X 2 bağımsızsa ve sırasıyla N q1 ( µ1 , ∑11 ) ve N q2 ( µ2 , ∑ 22 ) dağılırsa,
µ1 ∑11 M 0
X1
L ise N
M L
q1 + q2 L , L
µ 0 M ∑
X 2
22
2
(2.45)
şeklinde çok değişkenli normal dağılır (Johnson and Wichern 1992).
29
Sonuç 2.5 X rasgele değişkeni det(∑) > 0 olmak üzere N p ( µ , ∑) dağılır. O halde,
a) ( X − µ )′ ∑ −1 ( X − µ ) ifadesi p serbestlik dereceli ki-kare dağılır. ( χ (2p ) )
(2.46)
b) N p ( µ , ∑) dağılımı 1 − α olasılık ile { x : ( x − µ )′ ∑ −1 ( x − µ ) ≤ χ p2 (α )}
(2.47)
elipsine karşılık gelir.
Bunların nasıl oluştuğunu aşağıda sırasıyla göreceğiz.
a) Z1 , Z 2 ,..., Z p bağımsız rasgele değişkenleri N(0,1) dağılırken, Z12 + Z 22 + ... + Z p2
kareleri toplamı dağılımının χ (2p ) olduğunu biliyoruz. (2.48)’de ifade edilen Spectral
n
1
i =1
λi
Ayrışımlar yardımıyla A= ∑ ve ∑ −1 = ∑
ei ei′ elde edilir. Spectral Ayrışım kısaca
şöyle ifade edilir.
Bir A simetrik matrisi ( n × n ) boyutunda kare matris olsun. A matrisinin öz değerleri
sırasıyla λ1 , λ2 ,..., λn ve öz birim vektörleri ise sırasıyla e1 , e2 ,..., en olsun.
i = j ,
ei′e j =
i ≠ j ,
1
0
i = 1,2,…,n dir. O halde Spectral Ayrışım
A = λ1 e1 e1′ + λ2 e2 e2′ + ... + λn en en′
( n× n )
( n×1) (1× n )
( n×1) (1×n )
(2.48)
( n×1) (1× n )
şeklinde tanımlanır.
Burada ∑ ei = λi ei ’dir. Böylece ∑ −1 ei = (1/ λi )ei
Sonuç olarak,
p
p
( X − µ )′ ∑ −1 ( X − µ ) = ∑ (1/ λi )( X − µ )′ei ei′( X − µ ) = ∑ (1/ λi )(ei′ ( X − µ )) 2
i =1
i =1
p
p
i =1
i =1
= ∑ [(1/ λi )ei′ (X − µ )]2 = ∑ Z i2
(1/ λ )e ′
1 1
(1/ λ2 )e2′
A =
( p× p )
M
(1/ λ p )e p′
olarak belirttiğimizde
Z = A( X − µ ) ve X − µ ‘nin dağılımı N p (0, ∑) olur. Bu durumda,
Z1
Z
2
Z = ,
( p×1)
M
Z p
Z = A( X − µ ) değişkeni N p (0, A ∑ A′) şeklinde çok değişkenli normal dağılım gösterir.
30
(1/
(1/
A ∑ A′ =
( p × p ) ( p × p ) ( p× p )
(1/
λ1 )e1′
′
λ2 )e2 p
1
e1
∑ λi ei ei′
M
λ1
i =1
λ p )e p′
λ e′
1 1
λ e ′ 1
= 2 2
e1
M
λ
1
λ p e p′
1
λ2
e2 ...
1
λ2
e2 ...
ep
λ p
1
ep = Ι
λ p
1
Z1 , Z 2 ,..., Z p bağımsız standart normal değişkenler ve
( X − µ )′ ∑ −1 ( X − µ )
(2.49)
ifadesi p serbestlik derecesi ile ki-kare ( χ (2p ) ) dağılır (Johnson and Wichern 1992).
b) P[( X − µ )′ ∑ −1 ( X − µ ) ≤ c 2 ] olasılığı N p ( µ , ∑) ile dağılan ( X − µ )′ ∑ −1 ( X − µ ) ≤ c 2
elipsini ifade eder (Johnson and Wichern 1992).
Sonuç 2.6 X ~ N (µ , ∑) olmak üzere X ’in lineer dönüşümü olan,
U = AX + b
rasgele vektörü de normal dağılıma sahiptir. Gerçekten,
M U (t ) = E (et ′U ) = E (et ′( AX +b ) ) = et′b E (et′AX ) = et ′b M X ( A′t ) = et′b et′Aµ +(1/ 2)t′A ∑ (t′A)′
olmak üzere U rasgele vektörü,
U ~ N ( Aµ + b, A ∑ A′) dağılımına sahiptir (Akdeniz ve Öztürk 1996).
Sonuç 2.7 µ = 0 , ∑ = Ι olması durumunda N (0, Ι) dağılımına çok değişkenli standart
normal dağılım denir.
X ~ N (µ , ∑) olmak üzere, ∑:nxn kovaryans matrisinin ∑-1 invers matrisi kendi öz
değer ve öz vektörlerinin oluşturduğu matrisler cinsinden,
31
λ1 0 ... 0
0 λ ... 0
2
−1
P′
∑ = P
M M L 0
M M L λ p
olarak yazılsın ve
∑ −1/ 2
= P
λ1
0
...
0
λ2
...
M
M
L
M
M
L
0
0
P′
0
λ p
P = [e1 , e2 ,..., en ]nxn
olsun.
Z= ∑ -1/2 (Y-µ )
dönüşümü sonucu Z rasgele vektörü standart normal dağılıma sahiptir, yani
Z ~ N (0, Ι)
(2.50)
dır.
2.10.3 Çok Değişkenli Koşullu Dağılımlar
X 1 , X 2 ,..., X p rasgele değişkenleri için
X1
µ1
∑11 M ∑12
X = L vektörü, µ = L ortalamalı ve ∑ = L M L kovaryanslı normal
∑ 21 M ∑ 22
X 2
µ 2
dağılır. Yani,
X1
X = L ~ N p ( µ , ∑) dir.
X 2
X 1 = x1 verildiğinde X 2 nin koşullu dağılımı ortalaması ve kovaryansı sırasıyla
aşağıdaki gibi olan
−1
E X 2 X 1 = x1 = µ2 + ∑ 21 ∑11
( x1 − µ1 )
(2.51)
32
−1
Cov X 2 X 1 = x1 = ∑ 22 − ∑ 21 ∑11
∑12
(2.52)
ile normal dağılır. Bunu kısaca şöyle gösterebiliriz.
Ι
M
(( p − q ) x ( p − q ))
M
A= L
−1
− ∑ 21 ∑11 M
(( p − q ) xq )
L
Ι
( qxq )
0
(( p − q ) xq )
alalım. O zaman
X 1 − µ1
A( X − µ ) = A ........ =
X 2 − µ 2
X 1 − µ1
......................................
X − µ − ∑ ∑ −1 ( X − µ )
2
2
21
11
1
1
ifadesinin beklenen değeri E [ A( X − µ )] = AE [ X − µ ] = 0 ve kovaryans matrisi
0
∑11 M
Cov( A( X − µ )) = A ∑ A′ = .... M ......................
−1
0 M ∑ 22 − ∑ 21 ∑11
∑12
olan normal dağılıma sahiptir.
−1
Bu nedenle, X 2 − µ2 − ∑ 21 ∑11
( X 1 − µ1 ) ve A( X − µ ) in X 1 − µ1 olan iki bileşenin
kovaryansı 0’dır. Böylece onlar bağımsızdır. Üstelik,
−1
−1
X 2 − µ2 − ∑ 21 ∑11
( X 1 − µ1 ) ~ N p − q (0, ∑ 22 − ∑ 21 ∑11
∑12 )
şeklinde dağılmaktadır. Bağımsızlıktan
−1
−1
X 2 − µ2 − ∑ 21 ∑11
( X 1 − µ1 ) X 1 = x1 ~ N p − q (0, ∑ 22 − ∑ 21 ∑11
∑12 )
−1
−1
X 2 − µ2 − ∑ 21 ∑11
( x1 − µ1 ) X 1 = x1 ~ N p − q (0, ∑ 22 − ∑ 21 ∑11
∑12 )
dağılımlarını elde ederiz. Sonuç olarak
−1
−1
X 2 X 1 = x1 ~ N p − q ( µ2 + ∑ 21 ∑11
( x1 − µ1 ), ∑ 22 − ∑ 21 ∑11
∑12 )
(2.53)
dağılımı oluşur. Aynı şekilde X 2 = x2 verildiğinde X 1 in koşullu beklenen değeri,
kovaryansı ve dağılımı ise sırasıyla aşağıda gösterilmiştir.
E X 1 X 2 = x2 = µ1 + ∑12 ∑ −221 ( x2 − µ 2 )
Cov X 1 X 2 = x2 = ∑11 − ∑12 ∑ −221 ∑ 21
−1
X 1 X 2 = x2 ~ N p − q ( µ1 + ∑12 ∑ −221 ( x2 − µ2 ), ∑11 − ∑12 ∑ 22
∑ 21 )
dir.
33
(2.54)
2.10.4 Çok Değişkenli Normal Dağılımın Moment Çıkaran Fonksiyonu
Bir X rasgele vektörü normal dağılıma sahip olduğunda moment çıkaran fonksiyonu
M X (t ) = E (et ′X ) =
∞
∫ ... ∫
−∞
= e
t ′µ +
∞
−∞
1
(2π )
n
−1
det(∑ )
t′ ∑ t
2
e
( x − µ )′ ∑ −1 ( x − µ )
t ′x −
2
dx1...dxn
(2.55)
şeklindedir.
Burada µ ifadesi X rasgele vektörünün beklenen değeri olan ortalama vektörüdür. ∑
ise kovaryans matrisidir.
34
3. NORMAL DAĞILIMIN DİĞER DAĞILIMLARLA İLİŞKİSİ
Normal dağılımın diğer dağılımlarla olan ilişkisi Limit Dağılımı yardımıyla bulunur.
Bütün dağılımlar bazı şartlarda normal dağılıma yaklaşmaktadır.
Tanım 3.1 Her bir n = 1,2,… için ve X n rasgele değişkeninin dağılım fonksiyonu
Fn ( x) ve X rasgele değişkeninin dağılım fonksiyonu da F ( x) olsun. F ( x) dağılım
fonksiyonunun sürekli olduğu her x için
lim Fn ( x) = F ( x)
(3.1)
n →∞
ise X n rasgele değişkenler dizisi X rasgele değişkenine dağılımda yakınsıyor denir ve
d
X n
→ X ile belirtilir. Buna X n ’in limit dağılımı denir (Bain and Engelhardt 1989).
x<c
0
Tanım 3.2 F ( x) =
1
(3.2)
x≥c
ise x = c değerinde F ( x) fonksiyonu bozulan dağılımın dağılım fonksiyonudur (Bain
and Engelhardt 1989).
3.1 Stokastik Yakınsama.
X 1 , X 2 ,..., X n rasgele değişkenleri ve c bir sabit olmak üzere x = c’de limit dağılımına
sahipse buna stokastik yakınsama denir.
nb
c
lim 1 + = ecb
n →∞
n
(3.3)
nb
lim d (n) = 0
n →∞
ise
c d ( n)
cb
lim 1 + +
=e
n →∞
n
n
35
(3.4)
olur. (3.4) eşitliğinin her iki tarafının logaritmasını alarak kolayca çözebiliriz. (3.3)’deki
limite göre
c
c
nb ln 1 + = nb + ... = cb + ...
n
n
(3.5)
elde edilir. Burada n → ∞ iken terimlerin geriye kalan kısmı (artık değerler) sıfıra
yaklaşır (Bain and Engelhardt 1989).
3.2 Moment Çıkaran Fonksiyon Yaklaşımı
Moment çıkaran fonksiyon yaklaşımı ile çeşitli olasılık dağılımları normal dağılıma
yakınsamaktadır.
Teorem 3.1 X 1 , X 2 ,..., X n rasgele değişkenleri olsun. Dağılım fonksiyonları sırasıyla
F1 ( x), F2 ( x),..., Fn ( x) ve moment çıkaran fonksiyonları M 1 (t ), M 2 (t ),..., M n (t ) dır.
M(t),
F ( x) dağılım fonksiyonun moment çıkaran fonksiyonu bütün t için
lim M n (t ) = M (t )
n →∞
-h < t < h ise o zaman
lim Fn ( x) = F ( x)
(3.6)
n →∞
dır.
3.3 Ki-Kare Dağılımının Normal Dağılıma Yaklaşımı
X n rasgele değişkeni ki-kare dağılımına sahipse ortalaması n , varyansı 2n olduğundan
Merkezi Limit Teoreminde bu değerler yerine konarak moment çıkaran fonksiyon
yardımıyla normal dağılıma yaklaşmaktadır.
n → ∞ iken X n ~ χ (2n ) ise Z n =
Xn − n
2n
d
→ Z ~ N (0,1)
X n ~ χ (2n )
36
X n ’ nin moment çıkaran fonksiyonu (1 − 2t ) − n / 2 ,
t<
1
2
E( X n ) = n
V ( X n ) = 2n
Z n = ( X n − n) / 2n
X − n
M Zn (t ) = E exp t n
2n
=e
− tn / 2 n
M Zn (t ) = et
2/ n
E (e
tX n / 2 n
2
− t et
n
2 n
2t
) = exp − t
1 −
2n
n 2
2/ n
−n / 2
,t <
2n
2
−n / 2
, t<
2n
2
Taylor formülüne göre,
2
e
t 2/n
2 1 2 eξ ( n ) 2
= 1+ t
+ t
+
t
n 2 n
6 n
t 2 ψ ( n)
M Zn (t ) = 1 − +
n
n
3
−n / 2
2t 3eξ ( n )
2t 3 2t 4 eξ ( n )
ψ ( n) =
−
−
3n
3 n
n
lim iken limψ (n) = 0
n→∞
lim M Zn (t ) = et
2
/2
(3.7)
n →∞
Z n = ( X n − n) / 2n
standart normal dağılıma sahiptir. Yani ki-kare dağılımı bu
durumda standart normal dağılıma yakınsamış olur.
Teorem 3.2 De Moivre-Laplace Limit Teoremi. Binom dağılımına uyan X rasgele
değişkeni, yeterice büyük n defa bağımsız deneme yapılırken, meydana gelen başarılı
olay sayısı Sn olarak belirtilirse herhangi a < b için n → ∞ iken başarılan her sonuç p
olasılığı ile gerçekleşir.
37
Z=
Sn − np
(3.8)
np (1 − p)
ise
S n − np
≤ b → F (b) − F (a )
P a ≤
np (1 − p )
olur.
İspat 3.2 (3.8)’e göre, binom dağılımına sahip X rasgele değişkeni N (np, npq )
dağılımına yaklaşır. Burada q = 1 − p dir.
Sn in karakteristik fonksiyonu
E (eitSn ) = (q + peit ) n dir.
Bu durumda Z’nin karakteristik fonksiyonu ise
it ( S −np )/ npq
E (eitZ ) = E (e n
)
=e
−itnp / npq
= ( qe
itr / npq
−itnp / npq
it / npq n
E (e
)=e
( q + pe
)
−itp / npq
itq / npq n
+ pe
)
son eşitlikteki ifadeyi Taylor açılımı ile yazabiliriz.
(it ) 2
(it )n
it
e = 1 + it +
+ ... +
olduğunu hatırlarsak
2!
n!
n
2
t 2 t 2
lim f (t ) = 1− + d → e −t / 2
n→∞
2n n
(3.9)
olduğu görülüyor (Rao 1973). Açıkça, dağılım ortalaması 0 ve varyansı 1 olan normal
dağılıma yaklaşmaktadır. Deneme sayısı büyük olduğunda Binom olasılıkları normale
yaklaşır. Burada d(.) değeri artık değerdir.
38
3.4 t Dağılımının Normal Dağılıma Yaklaşımı
Tn , n serbestlik dereceli t dağılımına sahip olsun (n=1,2,3,…). Bunun dağılım
fonksiyonu
t
F(Xn) =
t
∫
−∞
f ( xn )dx = ∫
−∞
Γ [ (n + 1) / 2]
1
dx ,
π nΓ( n / 2) (1 + x / n)( n+1) / 2
2
(3.10)
dir. Burada f n ( x) ifadesi Tn ‘in olasılık yoğunluk fonksiyonu olarak tanımlanır. Buna
göre,
t
lim Fn (t ) = lim
n →∞
n→∞
∫
t
f n ( x)dx =
−∞
∫ lim f
−∞
n →∞
n
( x)dx
1 x 2 − n / 2
Γ [ (n + 1) / 2]
1
lim f n ( x)dx = lim
lim
1 +
.lim
n →∞
n →∞
n →∞ (1 + x 2 / n)1/ 2 n →∞
n
n
/
2
Γ
(
n
/
2)
2
π
n
2
x2
lim 1 + = e x
n →∞
n
t
lim Fn (t ) =
n →∞
∫
−∞
1 − x2 / 2
e
dx
2π
(3.11)
olduğundan standart normal dağılıma yaklaşmış olur (Hogg and Craig 1995).
3.5 Asimptotik Normal Dağılım
(m′′(ξ ) − σ 2 )t 2
m(t ) = 1 +
+
2
2
σ 2t 2
(3.12)
eşitliğine göre örneklem ortalaması standartlaştırıldığında Merkezi Limit Teoreminden
d
Z n
→ Z ~ N (0,1)
dir (Bain and Engelhardt 1989).
39
Tanım 3.3 X 1 , X 2 ,..., X n rasgele değişkenleri m ve c öyle sabit olsun ki,
Zn =
Xn − m
c/ n
d
→ Z ~ N (0,1)
n → ∞ iken X n , m asimptotik ortalama ve c 2 / n asimptotik varyanslı olarak
asimptotik normal dağılıma sahiptir (Bain and Engelhardt 1989).
3.6 Stokastik Yakınsamanın Özellikleri
Stokastik yakınsama, bilinmeyen kitle parametrelerinin iyi bir tahmini için gereken
özelliklere sahiptir.
Teorem 3.3 Her ε > 0 için X 1 , X 2 ,..., X n stokastik yakınsama lim P ( X n − c < ε ) = 1
n →∞
p
dir. Burada rasgele değişkenlerin sırası c sabiti için X n
→ c ile tanımlanan olasılıkta
yakınsamadır.
Teorem 3.4 X 1 , X 2 ,..., X n ortalaması µ ve varyansı σ 2 olan aynı dağılımlı rasgele
örneklem olmak üzere bu örneklemin ortalaması X olasılıkta µ ye yakınsar.
p
→µ
Yani X
dır.
(
)
İspat 3.4 E ( X ) = µ n , V ( X n ) = σ 2 / n ve P X n − µ < ε ≥ 1 −
(
)
lim P X n − µ < ε = 1
n →∞
σ2
ε 2n
(3.13)
40
dır. Bu sonuçlar kitle ortalamasını daha iyi tahmin etmeyi sağlayan örneklem
(
ortalamasını gösterir. X , n → ∞ iken P X n − µ < ε
herhangi bir ε > 0 ve 0 < δ < 1 için n >
(
)
değeri 1’e yaklaşır. Yani
σ2
ise
ε 2δ
)
P µ − ε < X < µ + ε ≥ 1−δ
dir.
d
d
Teorem 3.5 Z n = n ( X n − m) / c
→ Z ~ N (0,1) ise X n
→m
(3.14)
dir (Bain and Engelhardt 1989).
3.7 Limit Teoremleri
Bu bölümde limit teoremleri ve yakınsama teoremleri incelenecektir.
Tanım 3.4 Olasılıkta Yakınsama. Verilen herhangi bir ε > 0 sayısı için,
lim P X n − X < ε = 1 ise X n rasgele değişkeni X’ e olasılıkta yakınsamış olur ve
n →∞
p
X n
→ X şeklinde ifade edilir (Bain and Engelhardt 1989).
p
d
Teorem 3.6 X n rasgele değişkenler olmak üzere X n
→ X ise X n
→X
(3.15)
dir. X = c özel durumu için limit dağılımı P [ X = c ] = 1 olasılıkla bozulan bir dağılımdır
(Bain and Engelhardt 1989).
41
Teorem 3.7
p
X n
→c
ise herhangi g(x) fonksiyonu için c’de sürekli ise
p
g ( X n )
→ g (c )
(3.16)
dir (Bain and Engelhardt 1989).
İspat 3.7 Her ε > 0 ve g(x) c’de sürekli olduğu için burada ε > 0 öyle ifade edersek
x − c < δ , g ( x) − g (c) < ε mevcuttur.
P g ( x) − g (c) < ε ≥ P X n − c < δ
p
P( B ) ≥ P( A) olduğu için A ⊂ B . Fakat X n
→ c olduğu için her δ > 0 için
lim P g ( X n ) − g (c) < ε ≥ lim P X n − c < δ = 1
n →∞
n →∞
p
ve g ( X n )
→ g (c )
Bu teoremde X n ve c, vektörler k boyutlu olduğunda geçerlidir. Bu teorem çok
kullanışlıdır.
p
p
Teorem 3.8 X n
→ c ve Yn
→ d de X n ve Yn rasgele iki değişkenler ise
p
→ ac + bd
1) aX n + bYn
(3.17)
p
2) X nYn
→ cd
(3.18)
p
→1
3) X n / c
4) P[ X n ≠ 0] = 1
5) P [ X n ≥ 0] ise
c ≠ 0 için
Bütün n, c ≠ 0 için
(3.19)
1
1
p
→ dir.
Xn
c
p
X n
→ c dir.
(3.20)
(3.21)
(Bain and Engelhardt 1989).
p
d
Teorem 3.9 Stutsky’s Teoremi. Öyle X n
→ c ve Yn
→ Y ’de X n ve Yn iki
bağımsız değişkenler ise
d
1) X n + Yn
→c +Y
(3.22)
42
d
→ cY
2) X nYn
(3.23)
d
3) Yn / X n
→Y / c ; c ≠ 0
(3.24)
d
d
Teorem 3.10 X n
→ X ise herhangi bir g(x) sürekli fonksiyon g ( X n )
→ g( X )
dir.
Teorem 3.11
d
n ( X n − m ) / c
→ Z ~ N (0,1) ve g(x), x = m’de sıfırdan farklı türeve
sahipse yani g ′(m) ≠ 0 ise
n [ g ( X n ) − g ( m) ] d
→ Z ~ N (0,1)
cg ′(m)
(3.25)
standart normal dağılıma yaklaşır.
İspat 3.11 x ≠ m ve u(m)=0 ise
u ( x) = [ g ( x) − g (m)] /( x − m) − g ′(m)
p
u ( x) , u (m) = 0 ile m’de süreklidir. Böylece g ′(m) + u ( X n )
→ g ′(m)
n [ g ( X n ) − g (m) ] n ( X n − m ) [ g ′(m) + u ( X n )]
=
c
g ′(m)
[ cg ′(m)]
(3.26)
Asimptotik normalliğe göre n büyük olduğunda,
X n ~ N (m, c 2 / n) ise
2
c 2 [ g ′(m) ]
g ( X n ) ~ N g (m),
n
(3.27)
dağılımına yaklaşır.
43
4. NORMAL DAĞILIMDAN ELDE EDİLEN ÖNEMLİ SONUÇLAR
Karesel formların oluşumu için normal dağılımın özelliklerinden yararlanılarak bazı
dağılımlar elde edilmektedir. Bu dağılımlar ki-kare dağılımı, t dağılımı, F dağılımı ve
Wishart dağılımıdır. Bunlar aşağıda açıklanacaktır.
4.1 Ki-Kare Dağılımı
Teorem 4.1 X rasgele değişkeni
σ 2 >0 olmak üzere
N (µ , σ 2 )
dağılırsa,
W = ( X − µ ) / σ rasgele değişkeni standart normal dağılır. Yani N (0,1) ’dir (Hogg and
Craig 1995).
Teorem 4.2 X rasgele değişkeni N ( µ , σ 2 ) sahipse σ > 0 , V = ( X − µ ) 2 / σ 2 rasgele
değişkeni 1 sebestlik derecesi ile Chi-square ( χ 2 (1) ) dağılır (Hogg and Craig 1995).
Teorem 4.3 X 1 , X 2 ,..., X n rasgele değişkenleri N ( µ , σ 2 ) normal dağılımından n sayıda
bir rasgele örneklem olsun.
2
X −µ
rasgele değişkeni n serbestlik dereceli Ki-kare dağılımına sahiptir
Y = ∑ i
σ
i =1
n
n
Aynı şekilde Y =
∑(X
i
− X )2
i =1
σ2
rasgele değişkeni ise n-1 serbestlik dereceli Ki-kare
dağılımına sahiptir. Yani aşağıdaki gibi ifade edilir.
n
∑(X
i
− X )2
i =1
σ2
~ χ (2n −1)
(4.1)
dır.
44
Teorem 4.4 X 1 , X 2 ,..., X n N (0,1) ’den rasgele bir örneklem olmak üzere
U = X 12 + X 22 + ... + X n2 rasgele değişkeni n serbestlik dereceli ki-kare ( χ (2n ) ) dağılır.
Kısaca,
V = X 2 olsun.
1 1 −v / 2
1 −v / 2
e
+
e dv
2 v 2π
2π
1 −1/ 2 −1/ 2
v e dv
= 2π
0
,her v > 0 için
(4.2)
,diğer hallerde
Bu sonuçla v rasgele değişkeni 1 serbestlik dereceli ki-kare dağılır.
X 1 değişkeni N(0,1) dağılırsa X 12 değişkeni 1 serbestlik dereceli ki-kare dağılır. ( χ 2 (1) )
Aynı şekilde X 2 , X 3 ,..., X n değişkenleri N(0,1) dağıldığında,
X 22 , X 32 ,..., X n2 değişkenleri χ 2 (1) dağılır.
V1 = X 12 , V2 = X 22 ,..., Vn = X n2
U = V1 + V2 + ... + Vn ’in dağılımı ise
M V1 (t ) = (1 − 2t ) −1/ 2 = M V2 (t ) = (1 − 2t )−1/ 2 = ... = M Vn (t ) = (1 − 2t ) −1/ 2
M U (t ) = M V1 (t ) M V2 (t )...M Vn (t ) = (1 − 2t ) −1/ 2 (1 − 2t ) −1/ 2 ...(1 − 2t ) −1/ 2 = (1 − 2t ) − n (1/ 2)
= (1 − 2t ) − n (1/ 2)
(4.3)
Bu sonuçla U = X 12 + X 22 + ... + X n2 ’in dağılımı χ 2 ( n ) olur (Meyer 1970).
Ayrıca, X ~ χ (2n ) , X 1 ~ χ (2m ) , n > m, X 1 ile X 2 bağımsız ve X = X 1 + X 2 ise
2
X 2 = χ (n-m)
dır. Gerçekten, X 2 rasgele değişkeninin moment çıkaran fonksiyonu M X 2 (t ) olmak
üzere,
M X (t ) = M X1 (t ) M X 2 (t )
(1 − 2t ) − n / 2 = (1 − 2t )− m / 2 M X 2 (t )
ifadesinden
45
M X 2 (t ) = (1 − 2t )
−
n−m
2
2
oluşur yani, X 2 = χ (n-m)
dır.
Bundan başka, merkezi olmayan ki-kare dağılımı da vardır.
n
X ~ N (0, Ι n ) dağılsın. X ′X = ∑ X i2 merkezi ki-kare dağılımına sahiptir.
i =1
X ~ N ( µ , Ι) olduğunda U = X ′X dağılımını ele alalım. µ ≠ 0 olduğunda merkezi
olmayan ki-kare dağılımı oluşur. Burada,
1
1
µ ′µ = ∑ µi2 parametresi merkezi olmama
2
2
parametresi olarak bilinir. λ parametresi ile ifade edilir. Bu da λ =
µ ′µ
2
şeklinde
belirtilir. n serbestlik dereceli ve λ merkezi olmayan parametreli merkezi olmayan kikare dağılımı χ (2n ,λ ) ile gösterilir. Bu dağılımın olasılık yoğunluk fonksiyonu ise
∞
f ( x) = e− λ ∑
1
λk
x2
k!
1
n+k
2
k =0
2
1
n + k −1 − x
2
e
1
Γ n + k
2
(4.4)
şeklinde ifade edilir.
Merkezi olmayan ki-kare dağılımının moment çıkaran fonksiyonu
M X (t ) = e
−λ
∞
∑ (λ
/ k !)(1 − 2t )
k
1
− n + k
2
k =0
−1
= e− λ eλ (1− 2t ) (1 − 2t )
= (1 − 2t )
1
− n
2
1
− n
2
e− λ [1−(1− 2 t )
−1
]
(4.5)
biçiminde ifade edilir. Merkezi olmayan ki-kare dağılımının
Ortalaması
E ( X ) = n + 2λ
ve varyansı
V ( X ) = 2n + 8λ
dır. Dağılım merkezi olsaydı
46
Ortalaması E ( X ) = n
Varyansı V ( X ) = 2n
olurdu.
4.2 t Dağılımı
U ~ N(0,1) , V ~ χ (2n ) ve U ve V bağımsız iki rasgele değişken olmak üzere,
t=
U
V /n
(4.6)
rasgele değişkenin olasılık yoğunluk fonksiyonu
n +1
n +1
Γ
x 2 − 2
2
f ( x) =
, −∞ < x < ∞
1 +
2
n
π nΓ
2
(4.7)
dır. Bu olasılık yoğunluk fonksiyonuna sahip rasgele değişkenlere n serbestlik dereceli
t – dağılımı denir ve X ~ t( n ) biçiminde gösterilir (Akdeniz ve Öztürk 1996).
Teorem 4.5 t ~ t( n ) olmak üzere t nin limit dağılımı N(0,1) dır.
X ~ t( n ) olmak üzere,
E ( X ) = 0 , (n > 1)
(4.8)
ve
V (X ) =
n
, (n > 2)
n−2
(4.9)
d
t ~ t( n ) olmak üzere t
→ (Z ~ N (0,1))
n n→∞
dır.
47
(4.10)
Teorem 4.6 X 1 , X 2 ,..., X n rasgele değişkenleri N(µ ,σ 2 ) dağılımından bir örneklem
olmak üzere,
X −µ
~ t( n −1)
S/ n
(4.11)
şeklinde dağılır (Bain and Engelhardt 1989).
Teorem 4.7 X ~ N ( µ , σ 2 ) , U ~ χ (2n ) ve X ile U bağımsız olmak üzere,
X
µ
~ t n, δ =
σ
U /n
dır.
4.3 F – Dağılımı
U ~ χ (2r1 ) , V ~ χ (2r2 ) ve U ile V bağımsız iki rasgele değişken olmak üzere,
X=
U / r1
V / r2
(4.12)
rasgele değişkenin olasılık yoğunluk fonksiyonu
r1 + r2 r1
r +r
−1 2
Γ
r1 −1
2 r2 2 r1 2
x 1 +
,0 < x < ∞
,
f ( x) =
r2
Γ(r1 / 2)Γ(r2 / 2)
0
, diğer hallerde
(4.13)
dır. Bu olasılık yoğunluk fonksiyonuna ait rasgele değişkenlere F dağılımı denir ve
X ~ F (r1 , r2 ) biçiminde gösterilir.
Şimdi de merkezi olmayan F dağılımını inceleyelim.
U ~ χ 2 ( r1 ,λ ) , V ~ χ 2 ( r2 ) ve U ve V bağımsız iseler (4.12)’de ifade edilen rasgele
değişkeni r1 ve r2 serbestlik dereceli λ merkezi olmayan parametreli merkezi olmayan
48
F dağılımına sahiptir ve F ′(r1 , r2 , λ ) şeklinde gösterilir. Merkezi olmayan F dağılımının
olasılık yoğunluk fonksiyonu ise
r
r
1
2
+k
r1 r2
r1
2
2
+ k −1
r
r
+ +k
−λ k 1
2 Γ
∞
e λ
x2
2 2
f ( x) = ∑
1
( r1 + r2 + k )
k!
r
r
k =0
Γ 1 + k Γ 2 (r2 + r1 x) 2
2
2
(4.14)
şeklindedir. Beklenen değeri ve varyansı ise sırasıyla aşağıdaki şekilde ifade edilir.
E( X ) =
r2 (r1 + 2λ )
, (r2 > 2)
r1 (r2 − 2)
2
r (r + 2λ ) 2 + (r1 + 4λ )(−2)
V (X ) = 2 2 1
, (r2 > 4)
(r2 − 2) 2 (r2 − 4)
r1
dır. λ = 0 ve k = 0 olduğunda merkezi F dağılımı elde edilir (Searle 1997).
4.4 Wishart Dağılımı
Wishart Dağılımını ilk kez 1915 yılında Fisher bulmuştur. Bu bulgu iki boyutlu
vektörlere ilişkindir. Dağılımı ikiden fazla boyuta genelleştiren ve yoğunluk
fonksiyonunu 1928 yılında John Wishart bulmuştur. Bu sebeple bu dağılıma Wishart
Dağılımı denir (Tuncer 2002).
Tanım 4.1 Birbirinden bağımsız olarak X ~ N p ( µi , ∑) , i =1,2,…,p biçiminde farklı
yasalara göre dağılan
X 1 , X 2 ,..., X m gözlem vektörleriyle bunların dış çarpım
toplamlarından oluşan
m
C = ∑ X i X i′
(4.15)
i =1
matrisi düşünülsün. Pozitif tanımlı olan C matrisine “Wishart matrisi” adı verilip, “m
serbestlik derecesi”, “ ∑ parametresi” ve “ Λ merkezi olmama parametresi” ile merkezi
49
olmayan Wishart dağılımına sahip olduğu ifade edilir. Kısaca C ~ Wp (m, ∑; Λ ) ile
simgelenir. ∑ parametresi pozitif tanımlı simetrik bir matristir. Λ merkezi olmayan
parametresi de Λ = ∑ −1 MM ′ ’dir. Burada M matrisi
M = ( µ1 , µ2 ,...µm )
(4.16)
şeklinde pxm boyutundadır. M = 0 ya da
m
C = ∑ ( X i − µi )( X i − µi )′
(4.17)
i =1
durumunda merkezi bir Wishart dağılımı söz konusudur ve C ~ Wp (m, ∑) şeklinde
gösterilir (Tuncer 2002).
Tanım 4.2 Birbirinden bağımsız X i ~ N p ( µ , ∑) şeklindeki aynı dağılım yasasına göre
dağılan X 1 , X 2 ,..., X m gözlem vektörleri verilip,
m
K = ∑ ( X i − µi )( X i − µi )′
i =1
oluşturulsun. ∑
matrisinin pozitif tanımlı olması şartıyla
K
matrisinin cij ,
i ≤ j = 1, 2,..., n gibi belirgin elemanlarının dağılımı
1
1
det(k )( m − p −1) / 2 etr − ∑ −1 k
m/2
mp / 2 m
2
f K (kij , i ≤ j = 1, 2,..., p) = 2 Γ p .[ det(∑)]
2
0
, diğer hallerde
m
şeklindeki olasılık yoğunluk fonksiyonu yardımıyla belirlenir. Bu ifadedeki Γ p
2
simgesi “Çok Değişkenli Beta fonksiyonu” olarak da bilinen
m
Γp = π
2
p ( p −1)
4
p
m +1− k
2
∏ Γ
k =1
(4.18)
dir.
50
Tanım 4.3 α ∈ R p sıfırdan farklı sabit sayılardan oluşan bir vektör ve 4.17’de ifade
edilen C matrisi, C ~ Wp (m, ∑) ile bir Wishart matrisi olsun. Buna göre
χ m2 ~ χ (2mγ ) olmak üzere,
α ′Cα ile ((α ′ ∑ α ).χ m2 ) dağılımları birbirine eşittir (Tuncer 2002).
51
5. KARESEL FORMLAR
Bu kısımda karesel formların ne olduğu hakkında bilgi edineceğiz. Simetrik matrisli
karesel formlar çok değişkenli istatistik analizinde önemli yer tutar. Karesel formlar, p
boyutlu vektör uzayında küremsi, elipsimsi, v.b. geometrik kalıp oluştururlar. Sözü
edilen kalıplar, karesel formun “matris belliliği” adı verilen öz değerler kalıplarına
bağlıdır.
Tanım 5.1 f : R n → R bir fonksiyonda X : (nx1) boyutlu bir vektör ve A : (nxn)
boyutlu simetrik bir matris olsun. O zaman
n
n
f ( x) = X ′ AX = ∑∑ aij xi x j
(5.1)
i =1 j =1
şeklindeki forma karesel form denir. Burada
x1
x
X = 2 ve X ′ = [ x1
M
xn
a11
a
21
A=
M
an1
x2 L xn ] ve A matrisi de
a12 K a1n
a22 K a2 n
M
M
M
an 2 K ann
olmak üzere meydana gelen karesel form
= [ x1
x2
a11
a
K xn ] 21
M
an1
a12
a22
M
an 2
K a1n x1
K a2 n x2
M
M M
K ann xn
= X ′ AX
şeklinde ifade edilebilir. Burada A simetrik bir matris olduğundan A′ = A ’dır.
52
Tanım 5.2 X ve Y (nx1) boyutunda iki vektör olsun. X ′Y iç çarpımı X ve Y
arasındaki bileşenlerinin çarpımının toplamıdır.
X .Y = x1 y1 + x2 y2 + ... + xn yn = [ x1
x2
y1
y
K xn ] 2 = X ′Y
M
yn
X = Y olduğunda
n
X ′ X = ∑ xi2
i =1
şeklinde meydana gelen karesel form bileşenlerinin karelerinin toplamıdır (Basilevsky
1994).
( nxn ) boyutlu bir A simetrik matrisi ile n değişkenli f ( x) = X ′ AX karesel form olsun.
A matrisini diagonal yapacak bir Q ortogonal matrisi vardır. Q′AQ = D eşitliğinde D
diagonal matristir. Karesel form içinde X = QY değişimi yaparak
X ′ AX = (QY )′ A(QY ) = Y ′Q′AQY = Y ′ DY
şeklinde karesel form oluşur. Eğer A’nın öz değerleri λ1 , λ2 ,..., λn ise (5.2)’de D
diagonal olacak şekilde Q seçebiliriz.
λ1 L 0
D = M O M
0 L λn
(5.2)
Eğer y = [ y1 L yn ]′ ise yeni değişkenler
Y ′ DY = λ1 y12 + λ2 y22 + ... + λn yn2
karesel formu ile ifade edilir. Bu işleme diagonal bir karesel form denir (Poole 2003).
Teorem 5.1 Temel Eksen Teoremi. Her karesel form diagonal hale getirilebilir. ( nxn )
boyutlu simetrik bir A matrisi X ′ AX karesel formu ile incelenirse ve öyle bir
53
Q′AQ = D diagonal matrisi olacak şekilde bir Q ortogonal matrisi olursa, Y ′ DY
karesel formuna X = QY dönüşümü yapılıp X ′ AX karesel formu meydana gelir. A
matrisinin öz değerleri λ1 , λ2 ,..., λn ve y = [ y1 , y2 ,..., yn ]′ ise o zaman
X ′ AX = Y ′ DY = λ1 y12 + λ2 y22 + ... + λn yn2
karesel formu oluşur.
Tanım 5.3 f ( x) = X ′ AX şeklindeki bir karesel forma göre,
Bütün x için f ( x) ≥ 0 ise pozitif yarı tanımlıdır.
Bütün x ≠ 0 için f ( x) > 0 ise pozitif tanımlıdır.
5.1 Karesel Formların Dağılımı
Bu kısımda normal dağılıma sahip rasgele vektörlerin karesel formlarının olasılık
dağılımları incelenecektir.
X n×1 ~ N (0, Ι n ) olması durumunda,
X ′ X ~ χ (2n )
(5.3)
X n×1 ~ N (0, σ 2 Ι) olması durumunda da,
1
σ
2
X ′ X ~ χ (2n )
(5.4)
olduğunu biliyoruz.
Şimdi X n×1 ~ N (0, ∑) (rank ∑ = n) olmak üzere,
Q = X ′ ∑ −1 X
karesel formunun dağılımını bulmaya çalışalım. Q nun moment çıkaran fonksiyonu
(
′
M Q (t ) = E (etQ ) = E etX Σ
−1
X
)
54
∞
=
∞
∫ ... ∫
−∞
−∞
1
(
2π
) ( det Σ )
n
1/ 2
e
−
1− 2 t ′ −1
xΣ x
2
dx1...dxn = (1 − 2t ) − n / 2 , t < 1/2
olduğundan,
Q ~ χ (2n )
(5.5)
dır.
Bundan sonra X in dağılımı sırasıyla X ∼ N (0, Ι n ) ve X ∼ N (0, ∑) olması durumunda
X ′ AX gibi bir karesel formun merkezsel olmayan ki-kare dağılımına sahip olması için
A reel simetrik matrisinin sağlaması gereken özellikler elde edilecektir.
X ~ N ( µ , ∑) olması durumunda ise,
X ′ AX
gibi bir karesel formun merkezsel
olmayan ki-kare dağılımına sahiptir.
Teorem 5.2 X ∼ N (0, Ι n ) ve Anxn reel simetrik rankı r olan bir matris olmak üzere,
X ′ AX ~ χ (2r ) ⇔ A2 = A dır.
İspat 5.2 X ~ N (0, Ι n ) ve A reel simetrik bir matris olmak üzere
Q = X ′ AX
karesel formunu göz önüne alalım. Bu karesel formun moment çıkaran fonksiyonu,
(
′
)
M Q (t ) = E etX AX =
∞
∞
1
− x′ ( I − 2 tA ) x
1
−1/ 2
2
e
dx1dx2 ...dxn = [ det( I − 2tA)]
, t <h
n
(
2
π
)
−∞
∫ ... ∫
−∞
dır. Burada h sayısı, I-2tA matrisi pozitif tanımlı olacak şekilde sayıdır. A reel simetrik
bir matris olmak üzere, P ortogonal matrisi vardır, öyle ki
λ1 0 ... 0
0 λ 0 0
2
P′AP =
M M
M
0 0 ... λn
ve
det ( I − 2tA) = det ( P′( I − 2tA) P ) = (1 − 2t λ1 ) (1 − 2t λ2 ) … (1 − 2t λn )
55
dır. Rank(A) = r olsun. 0 < r ≤ n olmak üzere A matrisinin öz değerlerinden r tanesi
sıfırdan farklıdır, bunlar λ1 , λ2 ,..., λr olsun. O zaman,
M Q (t ) = [ (1 − 2t λ1 ) (1 − 2t λ2 ) … (1 − 2t λr ]
−1/ 2
dır. Q = X ′ AX karesel formunun dağılımı ki-kare olması için moment çıkaran
fonksiyonunun (1 − 2t ) − k / 2 biçiminde olması gerekir.
İlk önce Q = X ′ AX ~ χ (2k ) olduğunu varsayalım. Bu durumda,
[(1 − 2tλ1 )
(1 − 2t λ2 ) … (1 − 2t λr ) ]
−1/ 2
= (1 − 2t λ )− k / 2
olacaktır. Polinomların özdeş olması için r = k ve λ1 = λ2 = ... = λr = 1 olması gerekir.
Diğer öz değerlerin de sıfır olduğu göz önüne alınırsa A matrisi idempotent bir matris
olmalıdır.
Diğer taraftan X ∼ N (0, Ι n ) ve reel simetrik A matrisi için rank(A) = r, A2 = A , yani
idempotent ise,
M Q (t ) = (1 − 2t ) − r / 2
ve
Q = X ′ AX ~ χ (2r )
(5.6)
olacaktır (Akdeniz ve Öztürk 1996).
Teorem 5.3 (Cochran Teoremi) X ~ N ( µ , σ 2 Ι n ) dağılsın. A1 , A2 ,..., Ak matrisleri
simetrik, sırasıyla n1 , n2 ,..., nk ranklı ve A1 + A2 + ... + Ak = I n , yani
X ′ X = X ′ A1 X + X ′ A2 X + ... + X ′ Ak X
k
olsun. Eğer
∑n
i
= n ise,
i=1
X ′ A1 X , X ′ A2 X ,..., X ′ Ak X karesel formları bağımsız ve i = 1,2,...,n için,
1
σ
2
X ′ Ai X ~ χ 2
1
ni , λi = 2 µ ′ Ai µ
2σ
56
dır. Cochran Teoremi karesel formların parçalanmasında çok kullanışlı bir teoremdir.
k
Bu teoremdeki
∑n
i
= n olması şartı, Ai Aj = 0 , i≠j, i,j =1,2,...,n ya da Ai2 = Ai ,
i =1
i =1,2,...,n
olması şartlarına denktir.
Örnek 5.1 X nx1 ~ N (0, σ 2 I ) olsun. X vektörünün X 1 , X 2 ,..., X n bileşenlerine
N (0, σ 2 ) dağılımından alınmış n birimlik bir örneklem olarak bakabiliriz.
1
1
Jn =
M
1
1 L 1
1 L 1
, rank ( J n ) = n
M L M
1 L 1 n×n
ve
1/ n 1/ n L 1/ n
1/ n 1/ n L 1/ n
1
A = Jn =
M
M L M
N
1/ n 1/ n L 1/ n
olmak üzere,
nX
1
Q = X ′ 2 A X = 2
σ
σ
2
karesel formunu göz önüne alalım. rank(A) =1 ve
nX
σ2
2
2
~ χ (1)
(5.7)
dır. Ayrıca A matrisi simetrik ve idempotent olduğundan bir dik izdüşüm matrisidir.
Gerçekte,
1
1
1
+
1n = , 1n = [1,1,...,1]
M
n
1
+
A = 1n .1n
57
olmak üzere, A matrisi R n deki vektörleri 1n vektörünün gerdiği [ 1n ] alt uzayı üzerine
dik izdüşümü,
1/ n 1/ n L 1/ n X 1 X
1/ n 1/ n L 1/ n X
2 = X = X 1n
Xˆ = AX =
M
M L M M M
1/ n 1/ n L 1/ n X n X
Xˆ
2
2
= Xˆ ′ Xˆ = X ′ AX = n X
X̂ ile X − Xˆ vektörleri birbirine dik olduğundan,
X
2
= Xˆ
n
2
+ X − Xˆ
2
n
∑ X i2 = n X + ∑ ( X i − X )2
2
i =1
i =1
dır.
X
2
n
= ∑ X i2 = X ′ X de bir karesel formdur. Bu karesel formun matrisi, I birim
i =1
matrisidir. Bu karesel form ile ilgili,
1
X′ 2
σ
I X ~ χ (2n )
olduğu biliniyor.
n
∑(X
i
− X ) 2 de X ’in bir karesel formudur. Bu karesel formun matrisi,
i =1
B = In −
1
Jn
n
olmak üzere, bu matris simetrik, idempotent ve [1n ] alt uzayı üzerine dik izdüşüm
⊥
matrisidir.
n
1
X ′ BX = X ′ I − J n X = ∑ ( X i − X ) 2
n
i =1
B matrisi ile X ’in varyans kovaryans matrisi olan σ 2 I matrisinin çarpımı olan matrisi
idempotent yapmak için B yerine
1
σ2
B yazılmasıyla,
58
1
X ′ 2 B X ~ χ (2r )
σ
(5.8)
yazılır. Buradaki r serbestlik derecesi B matrisinin rankı olmak üzere aynı zamanda B
matrisinin sütun vektörlerinin gerdiği [1n ] alt uzayının boyutudur.
⊥
B matrisi idempotent olduğundan,
1
1
rank ( B) = tr ( B) = tr ( I n ) − tr ( J n ) = n − n = n − 1
n
n
ve buna göre,
n
1
1
X ′ 2 In − Jn X =
σ
n
∑(X
i
− X )2
~ χ (2n −1)
i =1
σ
2
(5.9)
dır (Akdeniz ve Öztürk 1996).
Örnek 5.2 Y ~ N (0, σ 2 I ) olsun. X n×r , rank(X) = r olmak üzere,
Q=
Y ′Y
σ2
, Q1 =
Y ′ X ( X ′X ) −1 X ′Y
σ2
, Q2 =
Y ′ ( I − X ( X ′X )−1 X ′)Y
σ2
karesel formların dağılımları,
1
Q = Y′ 2
σ
I Y ~ χ (2n )
X ( X ′X )−1 X ′ idempotent, rank( X ( X ′X )−1 X ′ )=tr( X ′X ( X ′X )−1 )= tr ( I r ) = r olduğundan
X ( X ′X ) −1 X ′
2
′
Q1 = Y
Y ~ χ(r )
2
σ
−1
ve I − X ( X ′X ) X ′ idempotent, rank ( I − X ( X ′X ) −1 X ′) = n − r olduğundan
1
Q2 = Y ′ 2 ( I − X ( X ′X )−1 X ′ ) Y ~ χ (2n − r )
σ
dır. Ayrıca,
X ( X ′X ) −1 X ′( I − X ( X ′X )−1 X ′) = 0
olduğundan Q1 ve Q2 karesel formları bağımsızdır.
Q1 n − r
~ F( r ,n − r )
Q2 r
dır.
(5.10)
59
Bir deney düzenlenirken bazı kitle değerlerinin tahmini veya bir hipotezin testi
düşünülür. Varyans Analizi kitlelerin ortalamaları hakkında sonuç çıkaran istatistiksel
işlemdir. Varyans Analizinin tek yönlü, iki yönlü ve çok yönlü olması faktör sayısına
bağlıdır. Bu durum bir lineer modeldir. Esas olarak, rasgele değişkenlerin dağılımında
dikkate alınan varsayımlar bağımsızlık, normallik ve eşit varyanslılıktır.
Esas analiz tekniği, kareler toplamının parçalanması ve test istatistiğidir. Test istatistiği
iki örneklem varyansının birbirine oranıdır yani F testidir (Chaing 2003).
5.2 Faktör, Faktör Düzeyleri ve İşlemler
Varyans Analizi modeli de kendine has bir terminolojiye sahiptir. Varyans Analizi
modelinin iyi anlaşılabilmesi için bu terminoloji geliştirilmelidir. Bu terminoloji faktör,
faktör düzeyi ve işlemden ibarettir.
Rasgele değişkeni etkileyen değişkenlere faktör, faktör elemanlarına ise faktör düzeyi
denilmektedir. İşlem, bir deneyde faktör düzeylerinin bileşenleridir (Sincich 1996).
5.3 Tek Yönlü Varyans Analizi ve Lineer Model (Tam Ranklı Olmayan Model)
Tek yönlü varyans analizinde rasgele değişkenler bir faktörün sınıflandırılması ile
tanımlanır. Örneğin k tür kanser tedavisinin etkinliği araştırıldığında, rasgele değişken
kanser hastalarının yaşam süresidir, faktör ise tedavi türüdür. Yaşam sürelerine, k
tedavi türü kitlelere bölünür. Yani k rasgele değişkenler Yi , (Y1 , Y2 ,..., Yk ) her bir tedavi
türüdür.
Y = Xβ +ε
(5.11)
modelini inceleyelim.
Y : (nx1) boyutlu gözlem vektörü.
β : ( px1) boyutlu parametre vektörü.
X : (nxp) boyutlu tasarım matrisi (0 ve 1 değerlerini alır).
60
ε : (nx1) boyutlu hata terimleri vektörü.
Öncelikle ε ‘yi inceleyeceğiz.
ε = Y − E (Y )
(5.12)
E (ε ) = 0
(5.13)
E (Y ) = X β
(5.14)
şeklinde beklenen değere ulaşılır.
ε ‘lerin varyansı eşittir ve σ 2 ‘dir. Yani
V (ε ) = E (εε ′ ) = σ 2 Ι n
(5.15)
Böylece,
ε ~ N (0, σ 2Ι) ve Y ~ N ( X β , σ 2Ι)
ile normal dağılır.
(5.11) modeli En Küçük Kareler ile tanımlanabilir.
X ′ X βˆ = X ′Y
(5.16)
yij = µ + α i + ε ij , j = 1, 2,..., ni i = 1, 2,..., k
(5.17)
Tek yönlü varyans analizinin lineer modelini incelersek,
µ : Kitle ortalaması
α i : i’nci faktörün etkisi
ε ij : Hata terimi
yij : Gözlem değerleri
yij rasgele değişkenleri bağımsız dağılmış olup, beklenen değeri
E ( yij ) = µ + α i , j = 1, 2,..., ni , i = 1, 2,..., k
(5.18)
ve σ e2 sabit varyanslı normal dağılmıştır. Sonuç olarak her bir hata terimi ε ij ise bu hata
terimleri E (ε ij ) = 0 beklenen değerli ve σ e2 varyanslı normal dağılıma sahiptir.
ε ~ N (0, σ e2 )
(5.19)
şeklinde ifade edilebilir.
(5.11)’de ifade edilen Y = X β + ε modeli yeniden incelenirse aşağıdaki şekilde ifade
edilebilir.
61
y11 1
y
12 1
M M
=
M M
M M
yij 1
ε11
1 0 L L
µ
1 0 L 0 ε12
α1
0 1 0 M M
α 2 +
M M 1 M M
M
M 0 M M M
α
0 0 0 1 i ε ij
(5.20)
Yine burada,
Y : Gözlem vektörü.
β : Parametre vektörü.
X : Tasarım matrisi (0 ve 1 değerlerini alır).
ε : Hata terimleri vektörü.
β ′ = [ µ α1 α 2 K α i ]
dir. Bunları çizelgede gösterebiliriz (Searle 1997).
Çizelge 5.1 Y = X β + ε modelinin parametreleri
Parametreler
Gözlemler
µ
α1
α2
α3
K
αi
y11
1
1
0
0
M
0
y12
1
1
0
M
M
0
M
M
0
1
M
M
M
M
M.
M
M
M
M
M
M
M
M
0
1
M
M
yij
1
M
M
M
M
1
Çizelge 5.1’de, α1 , α 2 , …, α i sütunlarının toplamı, (5.20) denkleminden açıkça
görüldüğü gibi µ sütun değerine eşittir. (5.16)’da ifade edilen denklemde X ′X karesel
form ve simetriktir, elemanları X ’in bileşenlerinin kareleri toplamıdır. Normal
denklemlere
X ′Y ’de dahildir, elemanları Y
çarpımlarıdır.
62
vektörü ile X ’in sütunlarının iç
n
n
1
X ′X = n2
M
ni
n2 L ni
M M 0
0 n2 M 0
M M O M
0 L L ni
n1
n1
1 1 L
1 1 0
X ′Y = 0 L 1
M M M
0 L L
(5.21)
L L 1 Y11 Y11 + Y12 + ... + Yij Y
L L 0 Y12 Y11 + ... + Y1 j Y1
L 0 M M = Y21 + ... + Y2 j = Y2
1 M M M
M
M
Y
L 1 1 Yij
Yij
i
(5.22)
(5.21)’de ifade edilen denklemde matrisin rankı ve parametre sayısı farklı olduğundan
(5.16)’daki normal denklemler
βˆ = ( X ′X ) −1 X ′Y
ile çözülemez. Bu denklemi
çözebilmek için matrislerin genelleştirilmiş inversinden yararlanarak
X ′X β 0 = X ′Y
(5.23)
normal denklemini yazarız.
β 0 parametresini bulmaya çalışacağız. X ′X ifadesinin rankı parametre sayısına eşit
olduğunda denklem çözülür. (5.23) denklemi GX ′Y yardımıyla çözülebilir. Burada G
X ′X matrisinin genelleştirilmiş inversidir (tersidir) ve
X ′XGX ′X = X ′X
(5.24)
şeklinde tanımlanır.
(5.21) ve (5.22)’ den oluşan normal denklemler
n
n
1
n2
M
ni
n1
n1
0
M
0
n2 L ni µ Y
0
M M 0 α1 Y1
n2 M 0 α 20 = Y2
M O M M M
L L ni α i0 Yij
0
şeklinde olur.
X ′X rankı parametre sayısına eşit olmadığı için X ′X ’in tersi yoktur ve (5.13)
ifadesinin çözümü yoktur. Yani tam ranklı olamayan modeldir. X ′X ’in genelleştirilmiş
inversi bulunarak
β 0 = GX ′Y
(5.25)
63
denklemi çözülür. Bu durum aşağıdaki teoremde daha kolay görülebilir.
Teorem. 5.4 A’nın bütün genelleştirilmiş inversi için, AX = Y denkleminden oluşan
bütün çözümler X = GY ’dir. (5.25) denkleminde β 0 notasyonu, (5.23) denkleminde
çözümü ile tanımlanmış denklem için bir çözümdür.
Yani,
µ 0 0
0
α1 y1.
0
β = α 20 = y 2.
M M
0
α a y a .
(5.26)
i = 1, 2,..., a için normal denklemlerin çözümü µ 0 = 0 ve α i0 = y i . dir.
X ′X ‘in genelleştirilmiş inversi G ise
0
0
G=
0 D {1/ ni }
(5.27)
dir. Burada D {1/ ni } ifadesi i = 1, 2,..., a için diagonal matristir.
5.4 Hata Terimleri Kareler Toplamı
Hata terimleri kareler toplamına Gruplar içi Kareler Toplamı da denilmektedir. Gruplar
içi Kareler Toplamı çalışma yapılan her bir grubun gözlem değerlerinin o gruba ait
örneklem ortalamasından olan sapmalarının kareleri toplamı olarak ifade edilir. Kısaca
HTKT veya GİKT ile gösterilir.
GİKT = ( y − X β 0 )′( y − X β 0 ) = Y ′ (Ι − XGX ′)′(Ι − XGX ′)Y
= Y ′ (Ι − XGX ′)Y
olarak hesaplanır. Çünkü Ι − XGX ′ idempotent ve simetriktir. Buradan da
GİKT = Y ′ (Ι − XGX ′)Y = Y ′Y − Y ′ XGX ′Y
64
= Y ′Y − β 0′ X ′Y
(5.28)
sonucuna ulaşılır (Searle 1997).
Aynı ifade aşağıdaki gibi de hesaplanır.
ni
k
GİKT = ∑∑ ( yij − y i ) 2
(5.29)
i =1 j =1
dir (Chaing 2003).
5.5 Toplam (Genel) Kareler Toplamının Parçalara Ayrılması
Genel Kareler Toplamı iki bileşenden oluşmaktadır. Bunlar Gruplar Arası Kareler
Toplamı ve Gruplar İçi Kareler Toplamıdır. GKT ile gösterilir.
k
ni
k
∑∑ ( y
ij
i =1 j =1
ni
k
ni
− y ) = ∑∑ ( yij − y i ) + ∑∑ ( y i − y ) 2
2
i =1 j =1
2
(5.30)
i =1 j =1
olarak ifade edilir. Buradan
n
GKT = ∑ yi2 − n y
2
i =1
(Chaing 2003). Yani
GKT = Y ′Y − n y
2
(5.31)
olarak hesaplanır (Searle 1997).
Gruplar Arası Kareler Toplamı ise Genel Kareler Toplamından Gruplar İçi Kareler
Toplamının farkıdır. GAKT ile gösterilir. Gruplar Arası Kareler Toplamı, örneklem
ortalamalarının genel ortalamadan olan farklarının kareleri toplamının örneklem hacmi
ile çarpımlarının toplamını vermektedir. (5.30) ifadesi kısaca
GKT = GİKT + GAKT
olarak da belirtilebilir. O halde Gruplar Arası Kareler Toplamı ise
GAKT = GKT – GİKT
(5.32)
olarak hesaplanır. (5.28)’de ve (5.31)’de bulunan değerleri (5.32)’de yerine koyarak
GAKT = (Y ′Y − n y ) − (Y ′Y − β 0′ X ′Y ) = β 0′ X ′Y − n y
2
şeklinde hesaplanır (Searle 1997). Aynı sonuç
65
2
(5.33)
k
ni
k
GAKT = ∑∑ ( y i − y ) 2 = ∑ ni ( y i − y ) 2
i =1 j =1
(5.34)
i =1
olarak da hesaplanır (Chaing 2003).
5.6 Dağılım Özellikleri
Hata terimleri normal, ortalaması sıfır ve eşit varyanslıdır.
ε ~ N (0, σ 2Ι n )
şeklinde ifade edilir.
a) Y rasgele vektörü normaldir.
Y = Xβ +ε
E (Y ) = X β
Y ~ N ( X β , σ 2Ι)
b) β 0 parametresi normal dağılır.
β 0 , Y ’nin lineer fonksiyonu olduğundan normal dağılır.
β 0 = GX ′Y ~ N ( H β , GX ′XG′σ 2 )
c) β 0 ve σˆ 2 bağımsızdır.
β 0 = GX ′Y ve GİKT = Y ′ ( I − XGX ′)Y
GX ′Ισ 2 (Ι − XGX ′) = G ( X ′ − X ′XGX ′)σ 2 = 0
olduğu için bağımsız oldukları ortaya çıkar.
d) GİKT / σ 2 ~ χ 2 ’ dir.
GİKT
σ2
GİKT
σ2
GİKT
σ2
=
Y ′ (Ι − XGX ′)Y
σ2
=
Ισ 2 (Ι − XGX ′)
σ2
= Ι − XGX ′
~ χ 2 k (Ι − XGX ′), β ′ X ′(Ι − XGX ′) X β / 2σ 2
~ χ (2n − k )
(5.35)
66
Hata terimleri (gruplar içi) kareler toplamının varyansa oranı (n-k) serbestlik dereceli
ki-kare dağılır. XGX ′ in özelliklerinden dolayı r ( x) = k dır.
e)
GAKT
σ
GAKT
σ
~ χ 2 dır.
2
2
JJ ′ ′
JJ ′
2
~ χ 2 k XGX ′ −
, β X ′ XGX ′ −
X β / 2σ
n
n
JJ ′
2
~ χ 2 k − 1, β ′ X ′ Ι −
X β / 2σ
n
(5.36)
dir (Searle 1997).
Çizelge 5.2 Y = X β + ε modeline uygun varyans analizi çizelgesi
Varyasyon
S. d.
Kareler Toplamı
Kareler
kaynağı
F İstatistiği
Ortalaması
Model
k-1
GAKT = β 0′ X ′Y − n y
(Gruplar arası)
k
=
∑n (y
i
2
GAKO =
GAKT
k −1
− y )2
i
i =1
Gruplar içi
n-k
GİKT = Y ′Y − β 0′ X ′Y
k
=
ni
∑∑ ( y
ij
F=
GİKO =
GİKT
n−k
GAKO
GİKO
− yi )2
i =1 j =1
Genel Kareler n-1
GKT = Y ′Y − n y
Toplamı
n
=
∑y
2
i
2
− ny
2
i =1
Çizelgede GAKO ifadesi Gruplar Arası Kareler Ortalamasıdır. Gruplar Arası Kareler
Toplamının k − 1 serbestlik derecesine bölümüdür ve
GAKO =
GAKT
k −1
(5.37)
şeklinde ifade edilir.
GİKO ifadesi ise Gruplar İçi Kareler Ortalamasıdır. Gruplar İçi Kareler Toplamının
n − k serbestlik derecesine bölümüdür ve
67
GİKO =
GİKT
n−k
(5.38)
şeklinde ifade edilir.
F istatistiği çizelgede görüldüğü gibi Gruplar Arası Kareler Ortalaması (5.37)’de ifade
edilen GAKO ’ nın, (5.38)’de ifade edilen Gruplar İçi Kareler Ortalamasına GİKO ’na
oranıdır ve aşağıdaki gibi ifade edilir (Searle 1997).
F=
GAKT /(k − 1) GAKO
=
~ F( k −1,n − k )
GİKT /(n − k ) GİKO
(5.39)
Bu işlemlerden sonra hipotez testi yapılır. Kitle ortalamaları arasında istatistiksel olarak
anlamlı farklılığın olup olmadığının test edilmesi gerekir. Önce hipotezler kurulur.
H 0 : µ1 = µ2 = ... = µk
H1 : En az iki kitle ortalaması farklıdır.
Hipotezler belirlendikten sonra test istatistiği hesaplanır ve ret bölgesi belirlenir.
Test istatistiği: (5.39)’da belirtildiği gibi F =
GAKO
GİKO
Ret bölgesi: F > Fα
Fα : α =0,05 veya α =0,01 anlam düzeyinde ve (k-1) ile (n-k) serbestlik derecelerine
göre F tablo değeridir.
F > Fα ise H 0 reddedilir. Bu durumda kitle ortalamalar
arasında istatistiksel olarak anlamlı farklılık olduğuna karar verilir. Ancak bu farklılığın
hangi kitle ortalamaları arasındaki farktan kaynaklandığı araştırılmak istenebilir. Bunun
için çoklu karşılaştırma testleri yapılır. Eğer H 0 kabul edilmiş olursa kitle ortalamaları
arasında anlamlı farklılık olmadığından çoklu karşılaştırma testleri yapılmasına gerek
kalmaz.
F testi yapılması için aşağıdaki varsayımların sağlanması gerekir. Bunlar:
1) Bütün kitlelerin olasılık dağılımı normaldir.
2) Kitlelerin varyansı eşittir.
3) Her bir kitleden rasgele alınan örneklemler bağımsızdır (Sincich 1996).
68
5.7 Çoklu Karşılaştırmalar
Daha önce de belirttiğimiz gibi F testi sonucunda H 0 reddedilirse yani kitle ortalamaları
arasındaki farkın anlamlı olduğu sonucuna varıldığında, bu farklılığın hangi gruplardan
ileri geldiğini belirlemek için çoklu karşılaştırmalar yapılmasına ihtiyaç duyulmaktadır.
Bunlar Fisher, Duncan, Tukey, Hartley, Student-Newman-Keuls ve Dunnett Testleridir.
En çok kullanılan yöntemler şunlardır:
1. Student Newman-Keuls Testi.
2. Duncan Testi
3. Scheffe Testi.
5.7.1 Student Newman-Keuls Testi
Varyans Analizinde gruplar arasındaki anlamlı farklılığın hangi gruplar arasındaki
ortalama farklarından olduğunu belirtmeye yarayan testlerden biri de Student NewmanKeuls Testidir.
Farz edelim ki k adet grup arasındaki farklılığı test edelim. Testi gerçekleştirmek için şu
adımlar izlenmelidir.
1) K ( p ) = q (α , p, n − k ) GİKO / ni
(5.40)
formülü ile hesaplanması söz konusu olan kriter belirlenmiş olur. Burada
α : 0,05 veya 0,01 olarak ele alacağımız anlam seviyesi
p: 2,3,…,k örneklem grubu sayıları
k: Grup sayısı
n: Bütün gözlemlerin mevcudu.
GİKO : Gruplar içi kareler ortalaması (5.38)’de ifade edilmiştir).
ni : İlgili gruba ait örneklem sayısı
69
Örneğin faktör sayısı 4 ise ilgilenilecek ortalamaların sayısı sırayla p = 2,3 ve 4
olacaktır. Bu bilgilere dayanarak q tablo değerlerini ve (5.40) ifadesini hesaplayarak
karşılaştırma yapılacak ölçütü belirlemiş oluruz. p = 2,3,4 ve α = 0, 05 olarak belirlenen
(5.40)’daki ifadeyi
K (2) = q (0, 05, 2, n − k ) GİKO / ni
K (3) = q (0, 05, 3, n − k ) GİKO / ni
K (4) = q (0, 05, 4, n − k ) GİKO / ni
şeklinde hesaplarız.
2) Gruplarının örneklem ortalamaları küçükten büyüğe sıralanır.
3) Farklar aşağıda belirtilen sıraya göre test edilir.
En büyük ve en küçük ortalama arasındaki fark
En büyük ve ikinci en küçük ortalama arasındaki fark
M
İkinci en büyük ve en küçük ortalama arasındaki fark
İkinci en büyük ve ikinci en küçük ortalama arasındaki fark
M
İkinci en küçük ile en küçük ortalama arasındaki fark alınır.
Belirlenen farkların anlamlılığını karşılaştırmak için en büyük ortalama ile en küçük
ortalama arasındaki aralık olan çalışmamızda söz konusu olan dört ortalamayı
kapsadığına göre, istatistiksel olarak anlamlı olması için “en küçük anlamlı aralık”
değerinden büyük olması gerekir. İkinci en büyük ile en küçük ortalama arasındaki
aralık üç ortalamayı kapsamaktadır; bunun da anlamlı olması için ikinci en büyük
değerden büyük olması gerekir. İkili olarak karşılaştırılan örneklem ortalamaları
arasındaki fark K(2), K(3) ve K(4) gibi değerlerden büyük olursa ilgili grupların
örneklem ortalamaları hakkında anlamlı farklar olduğu sonucu ortaya çıkar (Carmer and
Swanson 1973).
70
5.7.2 Duncan Testi
Duncan Testi, Newman-Keuls testine oldukça benzemektedir. Testin sonuçlanmasında
izlenen adımlar Newman-Keuls testi ile hemen hemen aynıdır. Sadece tablo değeri
farklıdır. Bu testi yapmak için şu aşamalar izlenir:
1) R( p) = r (α , p, n − k ) GİKO / ni
(5.41)
değeri hesaplanır.
Duncan testi için göz önünde tutulacak ortalama sayısına eşit serbestlik dereceleri için
anlamlı aralıklar belirlenir. Yaptığımız çalışmada grup sayısı 4 ise karşılaştırmada ele
alınacak ortalamaların sayısı sırasıyla 2,3 ve 4 olacaktır. Bu 3 tane ortalama sayısı için
belirlenen anlam düzeyinde anlamlı aralık değerleri belirlenir. Belirlenen değerlere göre
(5.41) eşitliği hesaplanır. α = 0, 05 ve p = 2,3 ve 4 için hesaplanacak ölçüt ise,
(5.41)’deki formül yardımıyla aşağıdaki gibi yapılabilir.
R(2) = r (0, 05, 2, n − k ) GİKO / ni
R(3) = r (0, 05, 3, n − k ) GİKO / ni
R(4) = r (0, 05, 4, n − k ) GİKO / ni
2) Örneklem gruplarının ortalamaları küçükten büyüğe sıralanır.
3) Farklar Newman-Keuls testinde yapılan işleme benzer şekilde alınır.
Sonuç olarak ortalamalar arası fark ilgili gruplar için hesaplanan (5.41) değerinden
büyük ise bu farklılığın hangi örneklem ortalamaları arasında olduğu belirlenir (Carmer
and Swanson 1973).
5.7.3 Scheffe Testi
Scheffe testi, örneklem hacimlerinin farklı olduğu durumda oldukça kullanışlıdır. Bu
testte bütün faktörlerin örneklem ortalamaları farkı ikişerli olarak hesaplanarak F testi
belirlenir. Belirlenen F test istatistiği daha önce bulunan F testindeki α = 0,05 değeri ve
(k-1) ve (n-k) serbestlik derecesine göre bulunan F tablo değeri ile karşılaştırılır.
71
Karşılaştırmalar sonucunda elde edilen bulgulara göre anlamlı farklılığın hangi faktörler
arasında olduğu tespit edilir. Bu test istatistikleri aşağıdaki şekilde ifade edilir.
Fij =
( yi − y j )2
(5.42)
1 1
GİKO + (k − 1)
n n
j
i
şeklinde hesaplanır. Burada
GİKO : (5.38)’de hesaplanan Gruplar İçi Kareler Ortalaması değeri
k : Grup sayısı
y i : Örneklem ortalamaları
ni : İlgili gruba ait örneklem hacmini ifade etmektedir.
Hesaplanan bu farkları daha önce bulunan kritik F tablo değerine göre karşılaştırırız. Bu
farklar ilgili anlam düzeyi ve serbestlik dereceleri ile belirlenen F tablo değerinden
büyükse ilgili grupların örneklem ortalamaları arasında bir farklılık vardır. Aksi halde
böyle bir farklılıktan bahsedilemez (Harris 1998).
72
6. UYGULAMA
2004-2005 öğretim yılı Bahar Dönemi Lisansüstü sınavına müracaat eden ve
19.12.2004 tarihinde Ankara Üniversitesi Türkçe ve Yabancı Dil Araştırma ve
Uygulama Merkezi (TÖMER) tarafından yapılan Ankara Üniversitesi Lisansüstü
(Yüksek Lisans-Doktora) Yabancı Dil sınavına giren öğrencilerin sınavdan aldıkları
başarı puanları arasındaki istatistiksel olarak anlamlı fark olup olmadığı incelenmek
istenmiştir. Sınava giren yabancı dili İngilizce olan 1029 öğrenciden 380 tanesi rasgele
seçilmiş olup bunlar arasından Fen Bilimleri, Sağlık Bilimleri, Sosyal Bilimler ve
Eğitim Bilimleri Enstitüsüne ait 95’er öğrencinin (toplam 380 öğrenci) sınav notu
incelenmiştir. Öğrencilerin başarı notları arasında anlamlı bir fark olup olmadığını
α = 0, 05 anlamlılık düzeyine göre inceleyeceğiz. Farklılık varsa bu farklılığın hangi
enstitü öğrencileri arasında olduğunu çoklu karşılaştırmalar testlerinden herhangi birini
uygulayarak belirleyeceğiz. Bu öğrencilerin yabancı dil sınavından aldıkları puanlar
çizelge 6.1’de gösterilmiştir.
Böyle bir problem Tek Yönlü ANOVA’ (Tek Yönlü Varyans Analizi) dır. ANOVA, F
dağılımına göre yapılır. F dağılımı karesel formlar yardımıyla oluşturulur. Başka bir
değişle bağımsız iki tane ki-kare dağılımının birbirlerine oranı F dağılımını oluşturur.
Bu amaçla pratikte en çok kullanılan testlerden biri de Varyans Analizidir. Yaptığımız
çalışmada 4 gruptaki (Fen, Sosyal, Sağlık ve Eğitim Bilimleri Enstitüsü) öğrencilerin
sınavdaki başarı notları incelenmiş her gruptan rasgele 95’er öğrenci seçilmiş, bu
öğrencilerin başarı notları arasında anlamlı bir farklılık olup olmadığı test edilecektir.
Aslında her gruptan 30’ar öğrenci alarak da araştırma yapılabilirdi. Ancak biz burada
daha açıklayıcı olması açısından ve daha fazla veri seçmeye elverişli olduğumuzdan
dolayı her enstitü için 95’er öğrenci seçmeyi uygun bulduk. Bunun için önce hipotezler
kurulacaktır. Kurulan hipotezler çözüm kısmında ayrıntılı biçimde ele alınacaktır.
Hesaplanan GİKT (5.28) ve GAKT (5.33) birer karesel formdur. Bu karesel formlar
(5.35) ve (5.36)’da belirtildiği gibi ki-kare dağılıma sahiptir. (5.37)’nin (5.38)’e oranı
(5.39)’da belirtildiği gibi F dağılımını oluşturur. Buna göre hipotez testi yapılır ve
gerekli işlemlerden sonra F test istatistiği hesaplanır. Elde edilen F test değeri ilgili
anlam seviyesi ve serbestlik derecelerine göre F tablo değeri ile karşılaştırılır. F test
73
istatistiği tablo değerinden büyükse H 0 hipotezi reddedilir. Öğrencilerin ortalamaları
arasında anlamlı bir farklılık olduğu ortaya çıkar. Test sonucunda 4 gruptaki
öğrencilerin başarı notları arasında anlamlı farklılık bulunmazsa çoklu karşılaştırmalar
testi yapmaya gerek yoktur. Ancak söz konusu gruplardaki öğrencilerin başarı notları
arasında anlamlı bir fark varsa bu farklılığın hangi gruplar arasında olduğunu tespit
etmek için çoklu karşılaştırmalar testleri yapılır. Biz bu karşılaştırma testlerinden birini
kullanarak farklılığın hangi enstitü öğrencileri arasında olduğunu belirleyeceğiz. Bu
farklılığın Fen Bilimleri ile Sosyal Bilimler arasında mı, Fen Bilimleri ile Sağlık
Bilimleri, Fen Bilimleri ile Eğitim Bilimleri arasında mı yoksa Sosyal Bilimler ile
Sağlık Bilimleri, Sosyal Bilimler ile Eğitim Bilimleri arasında mı veyahut Eğitim
Bilimleri ile Sağlık Bilimleri Enstitüsü öğrencilerinin başarı notları arasında olduğu
tespit edilecektir.
Karesel formlarla uygulama yapmak için normal dağılımla ilgili varsayımları da bilmek
gerekiyor. Bu varsayımlar 5.7. F Dağılımının Oluşturulması kısmında belirtilmiştir.
F dağılımında yani Varyans Analizi tablolarında hipotez testlerindeki test istatistiğini
oluşturan karesel formlar, bunların serbestlik dereceleri, beklenen değerleri gibi
sonuçlar toplu halde bulunmaktadır. Tablonun her satırı bir karesel form ile ilgilidir.
Her bir tabloda Y ′Y karesel formu ve σˆ 2 ile ilgili olan Y ′Y − βˆ ′ X ′Y karesel formu için
bir satır bulunmaktadır. Belli bir satırda karesel form ile ilgili bilgiler sütunlar halinde
verilmektedir. Varyans Analizi tablosunun ilk sütununda karesel formun ismi vardır.
İkinci sütununda kareler toplamları yani karesel formların kendileri, üçüncü sütunda
serbestlik dereceleri, dördüncü sütunda ortalama kareler toplamları ve son sütunda F
istatistiği yer almaktadır.
Uygulamayı karesel form yardımıyla yapmanın önemli avantajları vardır. Karesel
formlarla yapılan işlemler daha kolay ve anlaşılır olduğu için hata yapma olasılığı
hemen hemen yoktur. Ayrıca uzun hesaplamalar yapmayı gerektirmez. Bu durum
amacımıza daha kesin bir şekilde ulaşmamızı sağlar. Bu çalışmada karesel formlarla
yapılan çözümleme bu avantajlarından dolayı tercih edilir. Bu kolaylık araştırma yapan
istatistikçiler için önemli olduğu kadar, istatistikçiler dışındaki diğer okuyucular için de
ilgi konusu olabilir.
74
Çizelge 6.1 Ankara Üniversitesi Yüksek Lisans-Doktora sınavına müracaat eden
öğrencilerin yabancı dil sınavından aldıkları puanlar
Fen
Bilimleri
Enstitüsü
64
47
47
68
56
61
54
47
76
65
50
61
54
54
31
52
45
43
58
74
55
64
68
75
46
45
58
71
91
65
62
54
Sağlık
Bilimleri
Enstitüsü
67
55
80
63
74
87
33
46
85
35
72
62
53
51
71
60
73
59
91
57
54
66
40
41
69
84
83
37
70
50
53
42
Sosyal
Bilimler
Enstitüsü
69
35
75
63
52
82
78
49
45
79
78
62
40
50
87
80
58
46
34
68
85
81
41
62
65
56
49
53
57
46
79
49
Eğitim
Bilimleri
Enstitüsü
42
50
50
73
60
36
85
47
83
47
54
47
35
46
24
53
46
76
65
38
88
64
72
83
87
83
51
65
54
75
73
53
75
Çizelge 6.1 Ankara Üniversitesi Yüksek Lisans-Doktora sınavına müracaat eden
öğrencilerin yabancı dil sınavından aldıkları puanlar (devam)
Fen
Bilimleri
Enstitüsü
59
58
88
44
66
39
30
30
44
67
52
64
44
50
46
33
40
68
50
60
48
49
76
56
36
72
46
75
47
51
35
43
49
82
Sağlık
Bilimleri
Enstitüsü
73
48
59
74
55
51
25
46
79
72
78
76
57
62
39
31
66
54
68
64
73
76
69
61
55
75
45
72
47
40
81
35
74
76
Sosyal
Bilimler
Enstitüsü
60
61
48
64
57
66
54
91
59
63
38
69
76
72
72
90
89
37
74
84
81
84
65
49
67
38
80
80
30
72
44
72
83
65
Eğitim
Bilimleri
Enstitüsü
76
64
72
67
72
48
23
21
75
73
54
67
50
78
56
46
50
57
73
49
58
68
48
43
57
87
37
77
94
63
43
93
91
85
76
Çizelge 6.1 Ankara Üniversitesi Yüksek Lisans-Doktora sınavına müracaat eden
öğrencilerin yabancı dil sınavından aldıkları puanlar (devam)
Fen
Bilimleri
Enstitüsü
42
41
75
62
60
49
65
82
30
75
75
68
49
43
74
48
77
53
45
59
28
73
43
81
66
82
76
46
73
5398
56,82
Sağlık
Sosyal
Eğitim
Bilimleri
Bilimler
Bilimleri
Enstitüsü
Enstitüsü
Enstitüsü
47
48
70
56
46
74
79
76
60
56
42
55
28
61
70
63
51
61
50
56
78
52
65
37
50
54
43
59
78
65
51
87
63
55
38
63
55
87
61
70
54
47
74
59
24
47
90
78
64
81
54
37
60
39
50
84
44
57
44
64
45
57
64
74
69
53
72
58
51
72
49
69
94
74
58
69
77
42
74
35
53
79
70
77
50
64
36
Başarı Notları Toplamı
5748
6001
5673
Başarı Notları Ortalaması
60,51
63,17
59,72
77
Çözüm:
Sınava giren öğrencilerin yabancı dil sınavından elde ettikleri başarıları ölçmek için
hipotez testi yapmak gerekmektedir.
Önce hipotezleri kuralım ve varyans analizi tablosunu oluşturalım.
H 0 : µ1 = µ2 = µ3 = µ4 (4 Enstitü öğrencilerinin başarı ortalamaları aynıdır).
H1 : Kitle ortalamalarının en az ikisi farklıdır, ( µi ≠ µ j ) i, j = 1,2,3,4
(En az iki enstitü öğrencilerinin başarı ortalamaları farklıdır).
Burada;
µ1 = Fen Bilimleri Enstitüsü öğrencilerinin yabancı dil sınav başarı ortalaması
µ2 = Sağlık Bilimleri Enstitüsü öğrencilerinin yabancı dil sınav başarı ortalaması
µ3 = Sosyal Bilimler Enstitüsü öğrencilerinin yabancı dil sınav başarı ortalaması
µ4 = Eğitim Bilimleri Enstitüsü öğrencilerinin yabancı dil sınav başarı ortalaması
n1 = n2 = n3 = n4 = 95
n = n1 + n2 + n3 + n4 = 380 (Bütün gözlem sayısı)
k = 4 (Grup sayısı, yani Fen Bilimleri, Sağlık Bilimleri, Sosyal Bilimler ve Eğitim
Bilimleri Enstitüsü öğrencileri)
78
Çizelge 6.2 Yüksek Lisans ve Doktora sınavlarına giren öğrencilerin yabancı dil sınavı
başarı notlarının toplam ve ortalama değerleri
Enstitü
Fen Bilimleri
Sağlık Bilimleri
Başarı notları toplamı
n1
95
i =1
j =1
Eğitim Bilimleri
Genel Başarı
n1
y1 = ∑ y1 j =∑ y1 j = 5398
n2
y2 = ∑ y2 j =
j =1
Sosyal Bilimler
Başarı ortalaması
1j
y1 =
∑y
2j
= 5748
i =1
95
j =1
j =1
n4
95
i =1
j =1
y2 =
y4 = ∑ y4 j =∑ y4 j = 5673
nj
4
5398
= 56,821
95
i =1 j =1
i =1 j =1
∑y
=
5748
= 60,505
95
2j
j =1
n2
y3 =
y3 6001
=
= 63,168
n3
95
y4 =
y4 5673
=
= 59, 716
n4
95
k
95
Y = ∑ yi = ∑∑ yij = ∑∑ yij = 22820
i =1
n1
=
n2
y3 = ∑ y3 j = ∑ y3 j = 6001
k
j =1
95
n3
k
∑y
Y=
∑ ni y i
i =1
n
4
=
∑y
i
i =1
4
= 60,0526
Y = X β + ε modeline uygun olarak matrislerden yararlanarak çözmeye çalışalım. Bu
model aşağıda yeniden ele alınarak hesaplanacak ve istenen sonuca ulaşılacaktır.
Yaptığımız çalışmada ulaştığımız verilere göre,
64
47
M
Y =
M
77
36 (380 x1)
1
1
M
M
X =
M
M
1
1
1 0
M
M
0 1
M
M
M
0
M
M
M
M
0 0
L
M M
M M
M M
1 M
M M
0 1
L M
0
ε11
µ
ε
α
12
1
M
ε =
β = α 2
M
M
ε i1
α i
( i +1) x1
ε ij
olduğundan Y = X β + ε modeline uygun hale gelen işlemler aşağıda görülmektedir.
79
µ α1 α 2 α 3 α 4
1
1
64
47
M
M
M
Y =
=
M
M
77
M
36 (380 x1) 1
1
1 0
M M
0 1
M
M
0
M
M
M
M
0 0
=
Y
M
L
M M
M M
M M
1 M
M M
0 1
L M 380 x 5
0
µ
α
1
α 2 +
M
α k
5 x1
+ ε
β
X
ε11
ε
12
M
M
ε i1
ε ij
X: Tasarım matrisidir. Bu matrisin değerleri 0 ve 1 dir.
X tasarım matrisinin rankı 4’dür. Parametre sayısı da 5 dir. O zaman β̂ ’yı bulmak için
X ′Y = ( X ′X ) βˆ denklemlerinin çözümü genelleştirilmiş İnversler yardımıyla elde edilir.
Normal denklemleri tespit etmek için X ′ , X ′X ve X ′Y matrislerini oluşturalım.
1
1
X ′ = 0
M
M
1 L L L L L 1
M 0 L L L L L
M 1 L 0 L L 0
M M L 1 L 0 L
M L L L L 1 L 5 x 380
elde edilir.
1
1
X ′X = 0
M
M
1 L L
M
0
L
M
1
L
M
M
L
M L L
1
1
L L L 1
M
L L L L
M
0 L L 0
M
1 L 0 L
M
L L 1 L
1
1
1 0
M
M
0 1
M
M
M
0
M
M
M
M
0 0
şeklinde hesaplanır.
80
L
M M
380 95 95 95 95
M M
95 95 0 0 0
M M
= 95 0 95 0 0
1 M
95 0 0 95 0
M M
95 0 0 0 95
0 1
L M
0
1
1
X ′Y = 0
M
M
64
1 22820
47
L L L L 5398
M
0 L L 0 = 5748
M
1 L 0 L 6001
77
L L 1 L 5673
36
1 L L L L L
M
0
L
M
1
L
M
M
L
M L L
Burada β̂ ’yı hesaplamak için ve normal denklemleri oluşturacak gerekli olan matrisler
bulunmuştur. Bulduğumuz değerleri (5.16)’da ifade edilen aşağıdaki formülde yerine
koyarsak,
( X ′X ) βˆ = X ′Y
380 95 95 95 95 µˆ 22820
95 95 0 0 0 αˆ 5398
1
95 0 95 0 0 αˆ 2 = 5748
95 0 0 95 0 αˆ3 6001
95 0 0 0 95 αˆ 4 5673
elde edilir. Bu denklem sisteminden β̂ vektörünün tahmin edilmesi gerekir. Ancak bu
model tam ranklı olmayan bir modeldir. Yani X ′X matrisinin rankı ile parametre sayısı
birbirine eşit değildir. Burada X ′X matrisinin rankı, rank(x) = 4, parametre sayısı da
5’tir. Eğer X ′X matrisinin rankı ile parametre sayısı eşit olsaydı ( X ′X ) −1 matrisinin
tersi alınabilecekti ve β̂ vektörü tahmin edilebilecekti. β̂ vektörünün tahminine
(5.16)’da belirtilen denklemden elde edilen βˆ = ( X ′X ) −1 X ′Y ile ulaşılamaz. Çünkü
( X ′X ) −1 matrisinin inversi (tersi) alınamamaktadır. Bundan dolayı (5.25)’te ifade edilen
genelleştirilmiş invers yardımıyla β̂ vektörü tahmin edilecektir. O halde
genelleştirilmiş inversi G ile gösterilip hesaplanırsa
0
0
G = 0
0
0
1/ 95 0
0
0
0
1/ 95 0
0
0
0
1/ 95 0
0
0
0
1/ 95
0
0
0
0
elde edilir. βˆ 0 = GXY ′ eşitliğinden
81
X ′X ’in
0
0
βˆ 0 = 0
0
0
0
1/ 95
0
0
0
0
0
1/ 95
0
0
0
0
0
1/ 95
0
0 22820
0 5398
0 5748
0 6001
1/ 95 5673
0
0
5398 / 95 56,821
= 5748 / 95 = 60,505
6001/ 95 63,168
5673 / 95 59, 716
elde edilir.
Bulunan değerler yardımıyla F testini oluşturmak için GAKT, GİKT ve GKT’nin
hesaplanması gerekir.
Gruplar Arası Kareler Toplamının hesaplanması:
(5.33)’de hesaplandığı gibi,
GAKT = β 0′ X ′Y − n y (Gruplar Arası Kareler Toplamı)
2
dir. Burada n = 380 değeri sınava giren incelenen öğrenci sayısıdır ve y = 60, 0526 ise
sınava giren öğrencilerin genel başarı ortalamasıdır. Bu değerler formülde yerine
konursa
22820
5398
GAKT = [ 0 56,821 60,505 63,168 59,168] 5748 − 380(60, 0526)2
6001
5673
= 1372345,663 – 1370399,611=1946,663
bulunur. Aynı işlem (5.34’de belirtildiği gibi)
k
GAKT =
∑ ni ( y i − y )2 =
i =1
4
∑n (y
i
i
− y )2
i =1
= 95 x(56,82 − 60, 05) 2 + 95 x(60,51 − 60, 05) 2 + 95 x(63,17 − 60, 05) 2
+95 x(59, 72 − 60, 05)2 = 1946,663
şeklinde de hesaplanabilir.
Gruplar Arası Kareler Ortalaması (5.37’de ifade edilmiştir),
82
GAKT
= 1946,663 / 3 = 648,888
k −1
GAKO =
Gruplar İçi Kareler Toplamı (5.28)’de belirtilmiştir),
GİKT = Y ′Y − β 0′ X ′Y şeklindedir.
Bulunan değerler eşitlikte yerine konulursa
64
22820
47
5398
M
GİKT = [64 47 L L 77 36] − [ 0 56,821 60,505 63,168 59, 716] 5748
M
6001
77
5673
36
= 1464054 – 1372345,663 = 91708,337
elde edilir. Aynı işlem (5.29)’da belirtilen formül yardımıyla da hesaplanabilir.
k
GİKT =
ni
4
95
∑∑ ( yij − y j )2 = ∑∑ ( yij − y j )2
i =1 j =1
i =1 j =1
= (64 − 56,82)2 + (47 − 56,82) 2 + ... + (73 − 56,82) 2 + (67 − 60,51)2 + ...
+ (50 − 60, 51)2 + (69 − 63,17)2 + ... + (64 − 63,17) 2 + (42 − 59, 72) 2 + ...
+ (36 − 59, 72) 2
= 91708,337
dir.
Gruplar İçi Kareler Ortalaması ise (5.38’de ifade edilmiştir),
GİKO =
GİKT 91708,337
=
= 243,905
n−k
380 − 4
Genel Kareler Toplamı ise (5.31’de ifade edildiği gibi),
GKT = Y ′Y − n y =1464054-1370399,611 = 93654,389
2
olarak bulunur.
F istatistiğinin değeri (5.39)’da belirtildiği gibi,
F=
GAKT /(k − 1) GAKO
648,888
=
=
= 2, 66
243, 905
GİKT /( N − k ) GİKO
elde edilir.
83
Bu sonuçlara göre elde edilen Varyans Analizi Tablosu aşağıdaki gibidir.
Çizelge 6.3 Ankara Üniversitesi Lisansüstü Yabancı Dil sınavına giren öğrencilerin
başarı notlarına ilişkin Y = X β + ε modeline uygun Varyans Analizi
çizelgesi
Varyasyon Toplam
Kareler s.d
Kaynağı
Toplamı
Gruplar
βˆ 0′ X ′Y − n y
Arası
Gruplar
İçi
Toplam
2
Ortalama Kareler Toplamı F İstatistiği
4-1=3
GAKO =
1946, 052
= 648,888
4 −1
=1946,052
Y ′Y − βˆ 0′ X ′Y
380-4=376
GİKO =
91708, 337
= 243,905
380 − 4
F=
648,888
243, 905
= 2, 66
= 91708,337
Y ′Y − n y
2
380-1=379
= 93654,389
Hesaplanan F istatistiği F = 2,66 olup, F tablo değeri ise 0,05 anlam seviyesi, 3 ve 376
serbestlik derecelerine göre 2,60 dır. Yani Fhes = 2, 66 > 0,05 F3376 = 2, 60 olduğundan H 0
reddedilir. Fen Bilimleri, Sağlık Bilimleri, Sosyal Bilimler ve Eğitim Bilimleri
Enstitüsüne Lisansüstü yabancı dil sınavına giren öğrencilerin başarı notları arasında
istatistiksel olarak anlamlı bir fark olduğu ortaya çıkmıştır.
H 0 hipotezi kabul edilmiş olsaydı öğrencilerin sınavdaki başarı durumu hakkında
anlamlı bir fark olmayacaktı ve çoklu karşılaştırma testleri yapılmayacaktı. Ancak
burada H 0 hipotezi reddedildi ve öğrencilerin sınavdaki başarı durumları arasında
istatistiksel olarak anlamlı bir farklılık olduğu ortaya çıktı ve bu anlamlı farklılığın
hangi gruplardan kaynaklandığının gereği duyuldu. Bu farklılığın hangilerinden dolayı
ileri geldiğini belirlemek için daha önce de belirtildiği gibi çeşitli testler geliştirilmiştir.
Çoklu karşılaştırmalar testlerinde bahsedilen bu yöntemlerle öğrencilerin yabancı dil
sınavındaki başarıları arasındaki farklılığın hangi enstitü öğrencileri arasında
gerçekleştiği belirlenecektir.
Scheffe Testi yardımıyla bu farklılığın hangi enstitüdeki öğrenciler arasında olduğunu
bulmaya çalışalım.
(5.42)’de ifade edilen formül ile daha önce F testi için karşılaştırma yaptığımız 0,05
anlam düzeyi ve k-1 ile n-k serbestlik dereceleri ile belirlenen F tablo değerini
84
karşılaştırırız. Eğer (5.42)’deki değer, F tablo değerinden büyükse öğrencilerinin
sınavdaki başarıları arasında anlamlı farklılığın ilgili enstitü öğrencileri arasında olduğu
görülür. (5.42)’de ifade edilen formül yardımıyla gerekli hesaplamalar yapılır ve tablo
halinde verilebilir. Burada,
y1 = Fen Bilimleri Enstitüsü öğrencilerinin yabancı dil sınav başarı ortalaması
y 2 = Sağlık Bilimleri Enstitüsü öğrencilerinin yabancı dil sınav başarı ortalaması
y 3 = Sosyal Bilimler Enstitüsü öğrencilerinin yabancı dil sınav başarı ortalaması
y 4 = Eğitim Bilimleri Enstitüsü öğrencilerinin yabancı dil sınav başarı ortalaması
olup daha önce de hesaplandığı gibi,
y1 = 56,821
y 2 = 60,505
y 3 = 63,168
y 4 = 59, 716
n1 = n2 = n3 = n4 = 95
k=4
GİKO = 243,905
dir. Bu hesaplamalar aşağıdaki çizelgede görülmektedir.
85
Çizelge 6.4 Ankara Üniversitesi Lisansüstü Yabancı Dil sınavına giren öğrencilerin
başarıları arasındaki anlamlı farklılığın Scheffe testi ile çoklu
karşılaştırılması
Sonuç (Öğrencilerin
Enstitü
Fij =
( yi − y j )
2
1 1
GİKO + (k − 1)
n n
j
i
F tablo
değeri
başarıları arasındaki
Karşılaştırma anlamlı
hangi
farklılığın
gruplar
arasında olduğu)
Fen
Bilimleri-
Sağlık Bilimleri
Fen
Bilimleri-
Sosyal Bilimler
Fen
Bilimleri-
Eğitim Bilimleri
Sağlık BilimleriSosyal Bilimler
Sağlık BilimleriEğitim Bilimleri
Sosyal BilimlerEğitim Bilimleri
0,88
2,60
0,88 < 2,60
Anlamsız
2,62
2,60
2,62 > 2,60
Anlamlı
0,55
2,60
0,55 < 2,60
Anlamsız
0,46
2,60
0,46 < 2,60
Anlamsız
0,04
2,60
0,04 < 2,60
Anlamsız
0,77
2,60
0,77 < 2,60
Anlamsız
Sonuç olarak bu testte enstitü öğrencilerinin yabancı dil sınavında başarıları arasındaki
istatistiksel olarak anlamlı olan farklılığın Sosyal Bilimler Enstitüsü ile Fen Bilimleri
Enstitüsü öğrencileri arasında olduğu görülmektedir.
86
7. TARTIŞMA VE SONUÇ
Bu çalışmada öncelikle normal dağılımın bilinen temel özellikleriyle ilgili bilgiler
verildi. Normal dağılımın tarihçesi, yapısı, ortaya çıkışı ve özellikleri incelendi. Tek ve
çok değişkenli normal dağılımla ilgili önemli teoremler verilmiştir.
Bilindiği gibi normal dağılım istatistikte en önemli bir olasılık dağılımıdır. İstatistiksel
sonuç çıkarımlar normal dağılımdan elde edildiği için incelenen veriler ve değişkenler
normal dağılıma sahip olmasa bile limit dağılımı yardımıyla normal dağılıma
yaklaşmaktadır. Üçüncü bölümde bunun nasıl gerçekleştiğini limit dağılımı ve
yakınsama teoremleri yardımıyla gördük.
Dördüncü
bölümde normal dağılımdan elde edilen sonuçlar ifade edilmiştir. Burada
normal dağılımdan elde edilen istatistiksel dağılımlar incelenmiştir. Örneğin Ki-kare, t,
F ve Wishart gibi istatistiksel dağılımların nasıl ortaya çıktıkları ve nerelerde
kullanıldıkları görülmektedir. Normal dağılımdan elde edilen bu dağılımlarla daha iyi
sonuçlara ulaşarak uygulama yapmak mümkündür.
Beşinci bölümde karesel formlarla ilgili tanım, önemli teorem ve özellikler
açıklanmıştır. Karesel formlarla ilgili istatistikte neler yapılabileceği belirtilmektedir.
Karesel formlar da normal dağılımdan edilen önemli bir sonuçtur. Bir rasgele değişken
veya rasgele vektörün karesel formunun ki-kare dağıldığı, buna bağlı olarak da standart
normal dağılımın n serbestlik dereceli ki-kare dağılıma oranının t dağılımına sahip
olduğu, iki bağımsız r1 ve r2 serbestlik dereceli ki-kare dağılımların birbirine oranının
F dağıldığı görülmektedir. Wishart dağılımının ki-kare dağılımının genelleştirilmiş hali
olduğu görülmektedir. Yine Wishart dağılımının, ki-kare dağılımına ait özelliklerinin
birçoğuna sahip olduğu ifade edilmiştir.
Altıncı bölümde ise karesel formların dağılım özelliklerinden yararlanarak bir uygulama
yapıldı. Uygulamada, Ankara Üniversitesine Yüksek Lisans ve Doktora sınavlarına
müracaat eden öğrencilerin yabancı dil sınavında aldıkları notların başvuruda
87
bulundukları Enstitüye (Fen, Sağlık, Sosyal ve Eğitim Bilimleri) göre anlamlı bir
farklılık oluşturup oluşturmadıkları incelenmiştir. Sonuçta anlamlı bir farklılık olduğu
ve bu farklılığın Sosyal Bilimler Enstitüsü öğrencilerin aldıkları notlarla Fen Bilimleri
Enstitüsü öğrencilerin aldıkları notları arasında olduğu, çoklu karşılaştırma testleri
yapılarak saptanmıştır.
88
KAYNAKLAR
Akdeniz, F. ve Öztürk, F. 1996. Lineer Modeller, Ankara Üniversitesi Fen
Fakültesi Döner Sermaye İşletmesi Yayınları, No:38, 86-119, Ankara.
Bain, J. B. and Engelhardt M. 1989. Introduction to Probability and Mathematical
Statistics. PWS-KENT Publishing Company. Boston, 228-249.
Carmer and Swanson. 1973. IE 410 Lecture 6: More on Multiple Comparisons,
JASA Vol. 68. No: 341
Chiang, C. L. 2003. Statistical Methods of Analysis. World Scientific Publishing Co.
Pte. Ltd, 107-19, 349-354.
Conower, W. J. 1980. Practical Nonparametric Statistic, Second, Edition, Texas, Tech.
University, 357-364.
Harris, M.B. 1998. Basic Statistics for Behavioral Science Research, 334-357.
Hogg, V.R. and Craig T.A. 1995. Introduction to Mathematical Statistics. Prentice Hall,
Inc, 208-211, 238-239, 244-245.
Horrace, W. C. 2004. Some Results on the Multivariate Truncated Normal Distribution
Department of Economics, Syracuse University Working Paper Series, 1-16.
Johnson, R.A. and Wichern D.W. 1992. Applied Multivariate Statistical Analysis. New
Jersey, Prentice-Hall Inc, 129-142.
Lane, D. 2003. History of Normal Distribution. Connexions,
http://www.cnx.rice.edu/content/m11164/latest. Erişim Tarihi: 19.02.2004
Lehmann, E. L. 1986. Testing Statistical Hypotheses. Wiley series in probability and
mathematical statistics.
Lilliefors, H. W. 1967. “On the Kolmogorow-Smirnov” Test For Normality with Mean
and Variance Unknown JASA, 400 p.
Meyer, P. L. 1970. Introductury Probability and Statistical Applications. AddisonWesley Publishing Company, Inc, 183 p.
Pearson, A. V. and Hartley, H. O. 1972. Biometrica Tables for Statisticans, Vol 2.
Cambiridge, England.
Poole, D. 2003. Linear Algebra. A Modern Introduction. Trent Universty, 405-408,
USA.
89
Rao, C. R. 1973. Linear Statistical Inference and its Applications. Wiley series in
Probability and Mathematical Statistics, 158-163
Ross, S. 1997. A First Course in Probability. Prentice Hall, Inc, 355-358.
Searle, S.R.1997. Linear Models. N.Y. State College of Agriculture Cornell University,
Ithaca,N.Y, 175-177.
Shapiro, S. S. and Wilk, M. B., Chan, H. J. 1968. “A Comparative study of Various
Tests For Normality” JASA, 1343-1372.
Sincich, T. 1996. Business Statistics by Example. Prentice Hall, Inc, 273-275, USA.
Thomas, G. B. and Finney R. L. 1998. Calculus and Analytic Geometry. AddisonWesley Publishing Company, 1048-1053.
Tuncer, Yalçın. 2002. Çok Değişkenli İstatistik Analizine Giriş: Normal Teori.
Ankara Üniversitesi Fen Fakültesi İstatistik Bölümü, Bıçaklar Kitabevi, 72-83.
Ankara.
Zubrzycki, S. 1970. Lectures in Probability Theory and Mathematical Statistics.
American Elsevier Publishing Company, Inc, 183-184, New York.
90
ÖZGEÇMİŞ
Adı ve Soyadı : Şenol ÇELİK
Doğum Yeri
: Ilgın
Doğum Tarihi : 17.08.1969
Medeni Hali
: Bekar
Yabancı Dili : İngilizce
Eğitim Durumu (Kurum ve Yıl)
Lise
: Ilgın Lisesi (1984-1987)
Lisans
: Anadolu Üniversitesi Fen-Edebiyat Fakültesi İstatistik Bölümü
(1988-1992)
Yüksek Lisans : Ankara Üniversitesi Fen Bilimleri Enstitüsü İstatistik Ana Bilim
Dalı.
Çalıştığı Kurum/Kurumlar ve Yıl
Emniyet Genel Müdürlüğü Personel Daire Başkanlığı (1997-1998)
Emniyet Genel Müdürlüğü Trafik Araştırma Merkezi Müdürlüğü (1998’den bu yana)
Yayınları (SCI ve diğer)
91