Hatırlatma
Genlikte Ayrık Algılayıcı Yakınsama Teoremi
Eğitim kümesi doğrusal ayrıştırılabilir ise genlikte ayrık algılayıcı
için verilen öğrenme kuralı sonlu adımda bir çözüm verir.
Tanıt: c=1
X eğitim kümesindeki tüm girişler olsun
(1)
x ,x
( 2)
,...., x
Bu eğitim kümesine karşı düşen ağırlık vektörleri
(1)
( 2)
( k 1)
(k )
,.....
(k )
w , w ,...., w ,.....
w
(k )
olan adımlarda eğitim kümesindeki örüntüler
ve ağırlık vektörleri yukarıdaki dizilerden çıkarılsın
w
( j )T
x 0 ve x S1
Ağırlıkların güncellenmesi w
gereken her adımda ne
( j )T ( j )
( j)
w
x
0
ve
x
S2
oluyor?
( j)
( j)
Hatırlatma
Güncelleme sırasında neler olacak
( 2)
(1)
(1)
w w x
(3)
( 2)
( 2)
(1)
(1)
( 2)
w w x w x x
( 4)
(3)
(3)
(1)
(1)
( 2)
(3)
w w x w x x x
( k 1)
w
öğrenme
kuralı
w
(k )
x
(k )
w x
(1)
(1)
.... x
(k )
x S1
w x0
w(k 1) w(k ) x
x S2
w x0
w(k 1) w(k ) x
T
T
Eğitim kümesi doğrusal ayrıştırılabilir
çözüm kümesi w , w x 0
*
Bir w seçilsin
T
*T
ˆ min w x
xX
*T
ˆ w w(1)
*T ( k 1)
*T (1)
*T (1)
*T ( k )
w w
w w w x .... w x
T
w* w( k 1) k
2
T
*
w
w
( k 1) 2
*T
w w
( k 1)
Alt sınır
2
k
2
w
( k 1) 2
(k ) 2
* 2
w
w(i 1) w(i ) x(i )
(i 1) 2
w
(i 1)T
w
(i 1)
w
w
x
w
w
Neden?
( i )T ( i )
( i )T
0
w
w 2w
(i ) 2
(i 1) 2
( i )T ( i )
(i )
2w
(i ) 2
w
( i )T
x x
x
x
(i )
x
(i ) 2
( i )T ( i )
x
(i ) 2
Nasıl geldik?
i 1,2,3,...,k
w
( k 1) 2
k
x
(i ) 2
w
(1) 2
i 1
A ˆ max x
xX
2
(1) 2
Üst sınır
kA w
(1) 2
kA w
w
( k 1) 2
w
( k 1) 2
(k )
2
* 2
w
( k 1) 2
kA w
(1) 2
w
Alt sınır
Üst sınır
(k m ) 2
* 2
km A w
(1) 2
w
en büyük adım sayısı yukarıdaki eşitliğin
belirlediği km ‘den büyük olamaz
Genlikte Sürekli Algılayıcı
(ADALİNE)
Bernard Widrow-Tedd Hoff (1960)
x1
x1
w1
x2 w2
wn
xn
x2 w2
v
y
y
xn
wn+1
1
v w1
w1
1
w2 .... wn wn1
x1
x
2
.
.
.
xn
1
wn
wn+1
v w1x1 w2 x2 ... wn xn wn11
y (v) tanh av
1
y (v )
1 e av
x1
Genlikte Sürekli Algılayıcı için
Öğrenme kuralı
w1
x2 w2
wn
xn
v
y
wn+1
1
-
e
+ +
yd
Amaç: hatayı azaltacak ağırlıkları belirlemek
Hataya ilişkin bir fonksiyon oluşturularak işe başlanacak
Neden bir
e yd y
fonksiyon?
1 T
E e e ( yd y)T ( yd y) ( yd (v))T ( yd (v))
2
Nasıl azaltabiliriz?
Amaç: min E
n1
wR
Neden
vazgeçtik?
1 T
E e e ( yd y)T ( yd y) ( yd (v))T ( yd (v))
2
( yd ( w1 x1 w2 x2 ... wn xn wn11))T
( yd ( w1 x1 w2 x2 ... wn xn wn11))
Böylece E’nin w’ya bağımlılığını açıkça yazdık, acaba min E
n1
w
R
sağlayan w’ları nasıl buluruz?
E ( w( k 1) ) E ( w( k ) ) sağlayacak w( k 1) ‘i w(k ) ‘dan nasıl elde ederiz?
w(k ) ? w(k 1)
w( k ) cE w( k 1)
Nasıl
bulunur?
E ( w( k 1) ) E ( w( k ) )
v
E
w
w
1
1
v
E
w2
w2
E e y v
E ˆ
( yd y ) (v)
e y v w
v
E
wn 1
wn 1
x1
x
Öğrenme Kuralı:
2
w ( yd y) (v) x
( yd y ) (v)
1
Aktivasyon fonksiyonunu lineer alırsak ...
w ( yd y) (v) x
w ( yd y) x
Bir de girişleri normalize edersek ...
w ( yd y) (v) x
w ( yd y )
x
x
ADALINE’ı nerede kullanabiliriz
• sınıflandırma probleminde
1
Eğitim aşamasından sonra y
1
• yaklaşık eğri uydurma
• Lineer regresyon
n
wij xi 0
i 1
n
wij xi 0
i 1
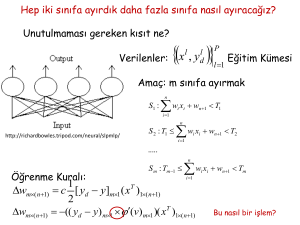
Hep iki sınıfa ayırdık daha fazla sınıfa nasıl ayıracağız?
Unutulmaması gereken kısıt ne?
Verilenler:
x ,
l
l
yd
P
l 1
Eğitim Kümesi
Amaç: m sınıfa ayırmak
n
S1 : wi xi wn 1 T1
i 1
n
http://richardbowles.tripod.com/neural/slpmlp/
S 2 : T1 wi xi wn 1 T2
i 1
.....
n
S 2 : Tm 1 wi xi wn 1 Tm
i 1
1
T
Öğrenme Kuralı: w c [ yd y]x
2
w (( yd y) (v))xT
Çok Katmanlı Algılayıcı-ÇKA
(Multi-Layer Perceptron)
Teorem: (Kolmogorov 1957)
f ( x1, x2 ,..., xn )
g ij (.)
h j (.)
xi [0,1]n , n 2
f ( x1 , x2 ,..., xn ) ‘e bağlı olmayan
monoton artan
sürekli
tek değişkenli fonksiyon
sürekli
tek değişkenli fonksiyon
n
f ( x1 , x2 ,..., xn ) h j gij xi
j1
i 1
2n1
Teoremin sonuçları.....
• Kolmogorov Teoremi bir varlık teoremi
f ( x1 , x2 ,..., xn ) ‘i özel bir şekilde ifade edebileceğimizi
söylüyor.
g ij (.)
ve
h j (.) ‘nin ne yapıda olduklarını ve kaç tanesinin
yeterli olacağını söylüyor.
• Kolmogorov Teoremi bir varlık teoremi olduğundan
h j (.) nasıl belirlenir söylemiyor.
g ij (.),
Kolmogorov Teoreminde bazı şeylerden vazgeçelim; tam
olmasın yaklaşık olsun ama fonksiyonları bilelim.
Teorem: (Cybenko 1989)
N yeterince büyük, j R , herhangi bir sürekli sigmoid
N
fonksiyon
f ( x1 , x2 ,..., xn ) ~
j w j T x j
j1
df
a, b R ve a b f : R R
0
dx
lim f ( x) a lim f ( x) b
f
x
Giriş
x
Gizli katman 1Gizli katman 2
Çıkış
http://www.oscarkilo.net/wiki/images/8/84/Ffperceptron.png
sigmoid
• Ağ yapısı
giriş katmanı
işlem yapan gizli katmanlar
işlem yapan çıkış katmanı
• Nöron
sürekli türetilebilir,
lineer olmayan aktivasyon
fonksiyonu var
• Eğitim
eğiticili öğrenme
• Öğrenme algoritması
geriye yayılım