YÖNETİM
BİLİŞİM
SİSTEMLERİ
7. Hafta Notu
Bilişim ve Veri Tabanları
Dersin Koordinatörü: Prof. Dr. Orhan TORKUL
Dersi Veren : Öğ.Gör.ERKAL ETÇİOĞLU
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
BİLİŞİM VE VERİ
TABANLARI
VERİ TABANLARI, VERİ AMBARI
ÖĞRENME ÇIKTILARI
Veri modellemede varlık-ilişki diyagramlarının rolü nedir?
Veri tipleri nelerdir ve hangi durumda hangi veri tipi kullanılmaktadır?
Veri tabanı nedir?
Bir bilişim sisteminde veri depolama için genellikle tek bir dosya niçin yetersizdir?
Veri tabanı modelleri nelerdir?
Veri tabanı tasarımı nasıl yapılır?
Veri ambarı nedir, ne işe yarar?
Sayfa 1
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
Veri Modelleme
Veri modelleme, bir işletmenin, kurumun hatırlamaya değer bulduğu verilerin şekil ve metin
olarak ifade edilmesidir. Diğer bir deyişle bir işletmede teknik ve teknik olmayan herkesin
bilişim ihtiyaçlarını ifade etmeye çalışırken birbirini anlamada kullanabileceği görsel bir
iletişim dilidir. Yazılım geliştirmenin en önemli süreçlerinden biri olan veri modelleme bilişim
ihtiyaçlarının keşfedilmesi ve herkesin anlayabileceği bir şekilde belgelenmesi işlemidir.
Bilişim ihtiyaçları, veriler ve işletme ihtiyaçlarını destekleyen işletme kurallarıdır. Bir veri
modeli herhangi bir işletmenin veya bir yazılımın karmaşık bilişim ihtiyaçlarının tümünü
yeterince ifade edebilmek için kullanılabilecek bir araçtır.
Veri modeli, sistemde ne tür verilerin ne şekilde tutulacağını tasarlayarak bilgi isteminden
elde edilebilecek çıktıları, başka bir deyişle bilgi sisteminin hareket kabiliyetini belirler. Veri
modeli, iş ortamında bulunan verinin tanımını, karakterini ve ilişkilerini ifade etmektedir.
Veri modellemenin amacı; verinin taşıdığı anlamı, veriler arasındaki ilişkileri, verilerin
niteliklerini ve verilerin net tanımlarını açıkça belirlemektir. Verilerin anlaşılabilmesi için en
iyi yolun veri modeli oluşturulması olduğu ifade edilmektedir.
Kullanıcıların bakış açısı dikkate alındığında bir bilişim sisteminde bilişimi organize etme ve
bilişime erişmeyle ilgili çoğu mesele şu 3 soru ile özetlenebilir:
Bilişim sisteminde ne tür bilgi vardır?
Bilişim nasıl organize edilir?
Kullanıcılar ihtiyaçları olduğu bilişim çeşidini nasıl elde edebilirler?
Bu üç sorunun cevabı veri modelleme ile çözülür. İlk iki soru varlık-ilişki diyagramlarının
temelini oluşturmaktadır.
Varlık-İlişki Diyagramları
Varlık-ilişki diyagramları, bir durumdaki varlık tiplerini belirlemede ve aralarındaki ilişkileri
diyagram ile göstermede kullanılan tekniktir. Veri tabanın hangi verileri içereceğinin ve nasıl
yapılandırılacağının belirlenmesine yardımcı olur. Kullanıcılar ve geliştiriciler arasında
mükemmel bir iletişim kanalıdır.
Varlık tipleri: sistemin, veri tabanında veriyle ilgili ne çeşit şeyler topladığıdır. Varlıklar,
veri ile alakalı toplanan belirli şeylerdir.
İlişki: varlıklar arasındaki ilişki veya birleşmelerdir.
Nitelikler: her varlık tipi için saklanan spesifik veri parçalarıdır.
Örneğin, bir üniversiteye kayıt sistemi kurulacağı düşünülürse, sistem ne tip bilişimlere
ihtiyaç duyar? Güncel sistemle uyumlu geliştirme düşünceleriyle birlikte bu soru 3 parçaya
bölünebilir:
Sistem bilişimi hangi tip şeyler hakkında toplar? Topladığı özel şeyler varlıktır. Bilişim
topladığı şeylere de varlık tipleri denir. Bir kayıt sisteminde varlık tipleri kurslar, öğrenciler,
profesörler vs. olabilir. Örnekte 6 varlık tipi bulunmaktadır.
Sayfa 2
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
Bu varlıklar arasındaki ilişki nedir? Bunların arasındaki ilişki birbirleri ile birleşmeleridir.
Mesela bir öğrenci birden çok kursa yazılabilir ve kurs sadece bir sınıfta olabilir.
Sistem bu şeyler hakkında hangi tipte özel bilişimler toplar? Varlıklar hakkındaki spesifik
bilişimlere nitelik denir. Öğrencinin varlık bilgisinde telefon, adres ve ödemediği harç bilgileri
olabilir.
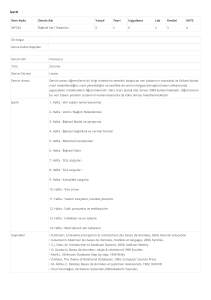
Şekil 1. Üniversite Kayıt Sistemi İçin Varlık-İlişki Diyagramı
Varlık-ilişki diyagramlarındaki ilişki tipleri şu şekildedir:
Bire-bir ilişki (her profesör bir ofise sahiptir ve her ofis bir profesöre tahsis edilir)
Bire-çok ilişki (her konu bir profesör tarafından öğretilir, ama her profesör birçok konu
öğretebilir)
Seçmeli bire-çok ilişki (her ders birçok konuya sahiptir, ama hiçbir konuya sahip olmayabilir
de)
Çoğa-çok ilişki (her öğrenci birçok konuyu alabilir ve her konu birçok öğrenci tarafından
alınabilir)
Kendisiyle ilişkili (bir ders birçok koşula sahip olabilir ve diğer dersler için koşul olabilir)
Örnekteki varlık tipleri bölüm, ders, konu (dönem), profesör, öğrenci ve ofistir. Bu varlık
tiplerinin olası nitelikleri ise şunlardır:
Sayfa 3
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
Tablo 1. Varlık Tipleri İçin Olası Nitelikler
Varlık Tipi
Bölüm
Ders
Konu
Profesör
Öğrenci
Ofis
Bu Varlık Tipinin Olası Nitelikleri
Fakülte
Başkan
Ders kodu
Bölüm
Ders tipi
Dersin tanımı
Kayıt kodu
Dönem
Yıl
Derslik
Başlangıç zamanı
Bitiş zamanı
Dersin günü
Çalışan kodu
İsim
Adres
Doğum tarihi
Ofis telefonu
Sosyal güvenlik numarası
Öğrenci kodu
İsim
Adres
Doğum tarihi
Telefon
Cinsiyet
Etnik grup
Ofis no
Bina
Varlık tiplerini ve aralarındaki ilişkileri tanımlandığımızda sistemde olması gereken bilişimi
irdelemek daha kolay olacaktır.
Veri modelleme, bir sisteme gerekli olan bilişimi tanımlamada yardımcı olur.
Diğer adım ise bu bilişimi bilgisayarlaştırılmış veri tabanına aktarmaktır. Bunun için verinin
tipi, verinin mantığı ve fiziksel görünüşü ve diğer anlamaya yardımcı olacak konular
gereklidir.
Veri Tabanı
Veri Tipleri
Günümüz bilişim sistemlerindeki 5 veri tipi şunlardır:
Biçimlendirilmiş veri: içeriği önceden açıkça belirlenmiş sayısal veya alfabetik öğeler
(ATM’ler, muhasebe sistemleri, sipariş takibi sistemlerinde bu veri tipi bulunur.)
Sayfa 4
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
Metin: içeriği önceden belirlenmemiş harfler, rakamlar ve diğer karakterler
Görüntü: görüntü, fotoğraflar, el yapımı resimler, grafikler
Ses: seslerden oluşmuş veri
Video: resimlerin ve seslerin kombine edilmiş hali
Geleneksel işletme bilişim sistemleri sadece biçimlendirilmiş veri ve metin tipini içerir.
Kütük/Dosya (File) Yapısı
Bilgiler YBS’lerde manyetik ortamlarda saklanmaktadır. Bilgisayar donanım ve yazılımdaki
gelişmeler çerçevesinde bilgi saklama ortamları da değişmekte ve gelişmektedir. Bu konuda
iki temel kavramdan bahsedilebilir. Bunlardan birinci kütük (file) yapısı diğeri ise çağdaş
yaklaşım olarak kullanılan veri tabanı (database) kavramıdır.
Bilgisayarların işletmelerde kullanılmaya başladığı yıllarda bilgiler Kütük (file) yapısında
saklanırdı. Bu kütüklerde bilgiler sıralı olarak yazılır ve yine sıralı olarak okunurlardı. Her
kütüğün kendine özgü bir yapısı (formatı) bulunurdu.
YBS açısından bilgileri kütüklerde saklamak oldukça zahmetli bir işlemdi. Bilgi girişleri zor
olmakta ayrıca girilen bilgileri güncelleştirmek içinde ayrıca programlar geliştirmek
gerekmekteydi.
Bu yöntem bilgi işlem çalışanlarına büyük yükler getirirdi. Her iş için ayrı ayrı kütüklerde
bilgiler tutulurdu. Kütük sayısı çoğalınca birbirleri arasındaki iletişim kopmakta, bilgiler
arasında uyumsuzluklar oluşmaktaydı. Bir kütükte güncellediğiniz bir bilgiyi ilgili diğer
kütüklerde yapmazsanız pek çok sorun çıkmaktaydı.
Günümüzde artık pek kullanılmayan bir bilgi saklama yöntemidir.
Veri Tabanı Sistemleri
Veri tabanı; belirli bir veri modeli ile saklanan, sistematik erişim imkanı olan, yönetilebilir,
güncellenebilir, taşınabilir, birbirleri arasında tanımlı ilişkiler bulunabilen bilgiler kümesidir.
Veri tabanları bilgisayarlar aracılığıyla kontrol edilir ve erişilir. 5 veri tipinden her birini
içerebilir. Veri tabanlarında, önceden tanımlı veri tipleri arasında önceden tanımlı ilişkiler
bulunur.
Veri tabanları çeşitli tiplerde olabilir ve çeşitli tiplerde kullanılabilir.
Veri tabanı yönetim sistemi (VTYS); veri tabanını tanımlamak, güncellemek ve kontrol etmek
için kullanılan geniş kapsamlı yazılım sistemidir.
Veri tabanı kullanmanın yararları şunlardır:
1. Veri tabanında bilgiler yinelenmez. Her kayıttan sadece bir tane vardır. Bunu açıklamak
istersek herhangi bir YBS’de müşterilere ait adresleri içeren bir veri tabanı varsa her
müşteri için tek adres bilgisi vardır.
Sayfa 5
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
2. Veri tabanında bulunan bilgiler standart hale getirilir. Yine aynı örnek üzerinde
açıklamak gerekirse her müşterinin adres bilgileri standart olur. Her müşterinin
bulunduğu ile Eskişehir ise hepsinde Eskişehir’dir. Bilgi girişinde yanlışlık yapılarak bazı
müşterilerde Eskişehir bazılarında Eskisehir bazılarında Eşkısehır gibi yanlış şehir ismi
olarak girilmez.
3. Veri tabanında bulunan bilgiler çeşitli kullanıcılar tarafından farklı işlemler için
paylaşılabilir. YBS içinde kurulmuş bulunan ve YBS’nin gerçekten en önemli parçasını
oluşturan veri tabanında bulunan bilgiler kullanıcıların amaçları doğrultusunda farklı
bakış acıları ile aynı anda kullanılabilir. YBS’deki veri tabanında yine müşterilere ait
bilgiler varsa bir kullanıcı müşterilere ait adresleri kağıt üzerine çıktı alırken bir başka
kullanıcı müşterilere ait hesap işlemlerini yapabilir. Veri tabanı üzerinde güvenlik sınırları
oluşturulur. Tüm bilgiler aynı yerde saklandığı için giriş ve çıkışlar kontrol altında tutulur.
İstenmeyen, güvenlik açısından sakıncalı kullanıcıların veri tabanına erişimi engellenir.
4. Veri tabanındaki bilgilerin periyodik olarak yedekleri alınır. Böylece istenmeyen
herhangi bir durumda bilgi kaybı en aza indirgenir.
Şekil 2. Veri Tabanının Çalışması
Veri Tabanı Kayıtları
Dosya; ilişkili kayıtlar bütünüdür.
Kayıt; aynı şey, insan veya olayla ilişkili alanlar bütünüdür.
Alan; önceden tanımlı bir anlama sahip karakter grubudur.
Anahtar; kaydı belirleyen eşsiz (özgün) alandır.
Sayfa 6
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
Veri Tabanı Yaklaşımı
Dosya İşleme Sistemi
Veri Tabanı Yaklaşımı
Kuruluştaki her bir bölüm veya alan kendi Birçok program ve kullanıcı veriyi bir veri
veri dosyası setine sahiptir.
tabanında paylaşır.
Uzun yıllardır kullanılır.
Veri artıklığını düşürür.
Veri artıklığı oluşur.
Veri bütünlüğünü artırır.
Fazlalık veri (kopya veri) oluşur.
Veriyi paylaşır.
Veriyi izole eder.
Kolay erişim sağlar.
Geliştirme zamanını azaltır.
Daha savunmasız (zarara açık) olabilir.
Daha karmaşıktır.
Özel eğitim, daha fazla bilgisayar belleği,
depolama alanı ve işleme gücü gerektirir.
Veri daha değerlidir.
Hangi Veri Tabanı Kullanmalı
Çok küçük veri depolama ihtiyacında: PARADOKS
Eğer bir web sitesinde veri miktarı ve aynı anda yapılan işlem sayıları az, küçük
yoğunlukta trafik varsa; basit web uygulamaları için: ACCESS, MYSQL
Daha büyük ve orta ölçekli uygulamalar için: PROGRESS, MS SQL, ya da Linux üzerinde
POSTGRESQL.
ORACLE ise çok yüksek güvenlik ve işlem gücü gerektiğinde tercih edilen bir veri tabanı
yönetim sistemidir.
Veri Modeli
Veri modeli, verileri mantıksal düzeyde düzenlemek için kullanılan yapılar, kavramlar ve
işlemler topluluğudur.
Her VTYS belirli bir veri modeli (ilişkisel, nesneye yönelik, çok boyutlu veri modelleri)
kullanır. En çok kullanılan veri modeli ilişkisel veri modelidir.
Veri tabanını tasarlayan kişi, veri modelinin yapılarını ve kavramlarını kullanarak mantıksal
düzeydeki düzenlemeleri oluşturur. Daha sonra o veri modelini kullanan bir VTYS üzerinde
bu düzenlemelere göre veri tabanı yaratılır.
İlişkisel Veri Tabanları
İlişkisel veri tabanı, veriyi satırlar ve sütunlardan oluşan tablolarda saklar. Her satır birincil
anahtara sahiptir. Her sütun eşsiz bir isme sahiptir. İki boyutludur.
İlişkisel veri tabanı geliştiricisi, bağlantı olarak bir dosyaya, değişkenler grubu olarak bir
kayda ve nitelik olarak bir alana başvurur.
İlişkisel veri tabanı kullanıcısı dosya olarak tablo, kayıt olarak satırları ve alan olarak da
sütunları kullanır. İlişki, bir ilişkisel veri tabanındaki verideki bağlantıdır.
Sayfa 7
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
İlişkisel veri tabanını çeşitli tablolar arasında organize edilmiş verilerden oluşan veri tabanıdır.
Bu farklı tablolar arasındaki veriler, çeşitli anahtarlar vasıtası ile birbirlerine bağlanırlar. İlgili
tablolarda, sütunlar arasında bir anahtar sütun yer alır. Bu anahtar sütun aracılığı ile birden
çok tablo verileri birbiriyle bağlantı sağlayabilir ve herhangi bir sorgulamada birlikte
görüntülenebilir. Bu tür veri tabanları arasında MySQL, Oracle, dBase, Progress, Informix,
Ingres, başta gelmektedir.
İlişkisel veri tabanı mantığı 1970 yılında Dr. Edgar F. Codd tarafından yazılan “A Relational
Model of Data for Large Shared Data Banks” adlı makalede ortaya atılmıştır. Bu makalede
Codd; ilişkisel mantığı tanıtarak, gerçek hayattaki nesnelerin tablo olarak nasıl ifade
edilebileceğini, bunların nasıl kullanılabileceğini anlatmıştır. İlişkisel sözcüğü veri tabanında
yer alan herhangi bir kaydın tek bir konu hakkında ve sadece o konuyla ilgili bilgileri içermesi
gerektiğini ifade eder.
İlişkisel veritabanlarındaki yapıda veriler tablolar halinde saklanır. Tablolar alanlardan (fields)
ve alanlardaki kayıtlardan (records) oluşur. İlişkisel veri tabanı modeli ‘Anahtar’ (key)
kullanarak farklı içerikteki tabloların birbirlerine bağlanmasına izin verir. Bir tablodaki alanlar
esas anahtar (primary key) olarak tanımlanabilirler. Kayıtlar ise tanımlanan anahtara göre
sıralanırlar. Tablolar arasındaki ilişkiler belirtilir ve bunlar matematiksel ilişkilerle (bağıntı)
temsil edilir. Bu ilişkiler iki tabloda da ortak bulunan alanlar aracılığıyla sağlanır. Ayrıca iki
farklı konuyla ilgili bilgiler, mesela teklifler ve o teklife ait kalem bilgileri (döviz fiyatı, döviz
kuru vs.), ilişkili veri değerlerine bağlı bir bütün olarak yönetilebilir. Örnek vermek gerekirse,
verilen her teklifin firma adı ve firma adresini saklamak gereksiz olur. Bir teklif numarası gibi
bir alan oluşturularak buna ait bilgileri kalem bilgilerinin bulunduğu tabloda tutarsak ve
bunları birbirine bağlarsak gereksiz kalabalıktan kurtulmuş oluruz. İlişkisel veritabanları
verinin hızlı geri alınımını sağlamasıyla birlikte daha birçok özelliğe sahiptir.
Şekil 3. İlişkisel Veri Tabanı
Sayfa 8
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
YAPILANDIRILMIŞ SORGU DİLİ (SQL)
Yapılandırılmış sorgu dili (SQL), ilişkisel veri tabanı modellerinde kullanıcıların veriyi
yönetmesine, güncellemesine ve okumasına izin veren bir sorgu dilidir.
SQL herhangi bir veri tabanı ortamında kullanılan bir alt dildir. SQL ile yalnızca veri tabanı
üzerinde işlem yapılabilir.
Örneğin, elimizde bulunan veri tabanından “17 numaralı bölümde çalışan sekreterlerin ad,
soyad ve adresleri” bulunmak isteniyor, bunun için aşağıdaki SQL kullanılabilir:
SELECT ADI, SOYADI, ADRESİ FROM PERSONEL WHERE BÖLÜMNO = 17 AND GÖREVİ
= ‘Sekreter’;
Nesneye Yönelik Veri Tabanı
Günümüzde pek çok kelime işlemci ve hesap tablosu programlarında kullanmaya alışılan
nesneler artık veri tabanı yönetim sistemi yazılımlarında da kullanılmaktadır. Yüzde yüz
nesneye yönelik bir yazılımın tamamen nesne temelli çalışması ve yazılımın mutlaka nesneye
yönelik bir dilde yazılmış olması beklendiğinden; nesneye yönelik veritabanları gerçek
anlamda bir nesneye yönelik yazılım değildirler. Nesneye yönelik veri tabanı, C++ gibi
nesneye dayalı bir dille yazılmış olan ve yine C++ gibi nesneye dayalı bir dille kullanılan veri
tabanı anlamına gelir. Günümüz teknolojisinde yüzde yüz nesneye yönelik bir veri tabanı
yaygın olarak kullanıma sunulmamış olmasına rağmen nesneye yönelik veritabanlarının bazı
üstünlükleri olacağından söz edilmektedir. Nesneye yönelik veritabanlarının ilişkisel
veritabanlarına göre sahip olması gereken üstünlükleri şunlardır:
Nesneler, bir tabloda yer alan bir kayıttan çok daha karmaşık bir yapıya sahiplerdir ve
daha esnek bir yapıda çok daha kullanışlı düzenlenebilirler.
Nesneye dayalı bir veri tabanında, yapısı gereği arama işlemleri çok hızlı yapılabilir.
Özellikle büyük tablolarla uğraşırken ilişkisel veritabanlarından çok daha hızlı sonuca
ulaşırlar. Ancak çalışma mantığı tümüyle değişir.
Tüm bu özellikler tamamen nesneye yönelik olan veritabanları için geçerlidir. Bazı ilişkisel
veritabanları ile çalışan yazılımlarda da nesnelerin bazı özellikleri kullanılırlar. Ama nesneye
yönelik veri tabanı bunu kendini ilişkisel veri tabanı kurallarına uydurarak gerçekleştirebilir.
ÇOK BOYUTLU VERİ TABANLARI
Çok boyutlu veri tabanları bilgi keşfi, görüntü işleme, veri madenciliği, örüntü tanıma ve
karar destek sistemleri gibi birçok uygulama alanında önem kazanmaktadır. Günümüzde veri
tabanı yönetim sistemleri eski örneklerine göre çok daha karmaşıktır. Modern uygulamalarda
veri tabanı kavramı yalnızca ilişkisel veya nesne yönelimli olarak iki türe değil, uygulama
alanlarına özel birçok farklı türe ayrılmaktadır.
Çoklu Ortam Veri Tabanları
Çoklu ortam veri tabanları birçok farklı biçimde görüntü, ses ve video verileri içerirler.
Fotoğrafik görüntüler, uydu görüntüleri, uzaktan algılama resimleri, tıbbi görüntüler (iki
Sayfa 9
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
boyutlu X ışınları ve üç boyutlu beyin MRI taramaları), jeolojik görüntüler, biyometrik
tanımlama görüntüleri (parmak izi, retina) gibi farklı çoklu ortam verileri depolamak üzere
özelleştirilmiş birçok uygulama bulunmaktadır. Bu uygulamalarda amaç, hedef olarak
seçilmiş bir nesneye en fazla benzeyen nesneleri bulmaktır. Bu sebeple her görüntü renk, şekil,
desen gibi özelliklerden oluşan özellik vektörlerine dönüştürülür. Benzerlik, özellik vektörleri
arasındaki uzaklık hesaplanarak bulunur.
Şekil 4. Çok Boyutlu Veri Tabanı
Zaman Serileri Veri Tabanları
Bu veritabanları finansal, tıbbi ve bilimsel verilerin analizinde, veri madenciliğinde ve karar
verme sürecinde kullanılırlar. Zaman serileri veri tabanları zaman serisi şeklindeki verileri
ayrık fourier dönüşümü veya ayrık dalgacık dönüşümü dönüşüm yöntemleri ile çok boyutlu
noktalara dönüştürürler. Benzerlik arama işlemi dönüştürülmüş veriler üzerinde
gerçekleştirilir.
DNA Veri Tabanları
Genetik materyal (DNA) bir canlının tüm hücresel fonksiyonları için gerekli tüm bilgileri
depolamaktadır. DNA, dört harfli alfabesi olan bir metin dizisidir. Bu dört harf A, C, G ve T
olarak dört farklı çeşit nükleotidi temsil eder. Yeni bir metin dizisi (örneğin bilinmeyen bir
Sayfa 10
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
hastalığa ait olabilir), eski dizilerin herhangi bir bölümü eşleştirilmeye çalışılır. Eşleştirmenin
amacı belirli bir uzaklık fonksiyonu kullanılarak aranan metne en fazla uyan bölümü
bulmaktır.
Doküman Veri Tabanları
Bu veritabanları çoğunlukla belirli bir dile ait kelimeler veya metinlere ait özellik vektörleri
içerirler. Çok fazla sayıda boyuta sahip olabilirler. İnternet’in doğuşu ile birlikte gelişme
göstermiştir. İnternet arama motorları, on-line veritabanları, doğal dil işleme, doküman
sınıflandırma gibi alanlarda yoğun olarak kullanılmaktadır.
Yukarıda açıklanan veritabanları çok boyutlu veri nesnesi şeklinde temsil edilen ve sayısal
verilerden oluşan özellik vektörlerine sahiptir. Bu yüzden bu tür veritabanlarına genel olarak
“çok boyutlu veri tabanı” adı verilir. Çok boyutlu veri tabanları, anahtar (key) ifade tabanlı
geleneksel sorgular yerine “benzerlik tabanlı” veya içerik tabanlı bilgi çekme sorgularına
gereksinim duyarlar. Bu tür veri tabanlarında benzer örüntüler arama süreci büyük önem
taşır. Çünkü bu süreç tahmin etme, karar verme, bilgisayar destekli tıbbi muayene, hipotez
doğrulama ve veri madenciliği için kritik öneme sahiptir.
Veri Ambarı Tasarımı
İyi bir veri tabanı tasarımı yapabilmek için yetenek, bilgi ve tecrübe çok önemlidir. Bir veri
tabanı ile proje yapılırken işin en önemli aşaması veri tabanının tasarlanmasıdır. Başlangıçta
yanlış tasarlanan bir veri tabanı ile yapılan projede sonradan yapılacak düzenlemelerle geri
dönüş yapılamaz. O nedenle veri tabanı tasarımı yapılırken aşağıdaki maddelere uyularak
yapılması gerekir.
Nesnelerin Tanımlanması
Nesne, çeşitli özellikleri bulunan bir varlıktır. Herhangi bir proje de öncelikle nesneler
tanımlanır. Birkaç proje için nesnelere örnek verilecek olunursa,
Kütüphane sistemi: Kitap, üyeler, türler, ödünç hareketleri.
E-ticaret sistemi: Ürünler, müşteriler, siparişler, teslimat, fatura bilgileri, üreticiler,
tedarikçiler, dağıtıcılar.
Futbol Ligi: Takımlar, sahalar, oyuncular, fikstür, hakemler, antrenörler.
Okul Sistemi: Öğrenciler, öğretmenler, dersler, derslikler.
Personel Sistemi: Çalışanlar, meslekler, çalışılan birimler, maaşlar, izinler.
Sözlük: kelimeler, anlamlar, diller.
Tablolara isim verilirken mümkünse tekil isimler kullanılmalıdır. Böyle yapılırsa; hem daha
anlaşılır bir tasarım yapılmış olur hem de daha sonra kodlama aşamasında karışıklığın önüne
geçilmiş olur.
Her Nesne İçin Tablo Oluşturması
Her nesne için bir tablo oluşturulur ve her bir tabloya içereceği veriyi en iyi anlatan bir isim
verilir. Tablo oluşturma işi, bir kâğıt üstünde sembolik olarak gösterilebilir veya doğrudan MS
Sayfa 11
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
Access, SQL Server, MySQL, Oracle gibi kullanılmakta olunan VTYS üstünden de
oluşturulabilir. Tüm proje bitirilinceye kadar bu tablolar üzerinde muhtemel değişiklikler
yapılabilir.
Her Bir Tablo İçin Bir Anahtar Alan Seçilmesi
Veri tabanındaki herhangi bir veriye erişilmeden önce tabloya erişilir. Bir veri tabanında
üzerinde en çok işlem yapılan nesne grubu genellikle tablolardır. Bu aşamaya kadar hangi
tabloların oluşturulacağına karar verildi. Her bir tablonun içinde hangi bilgilerin saklanılacağı
kabaca tasarlanır. Bu aşamada, tabloda yer alacak her bir kaydı bir diğerinden ayırabilecek bir
sütuna ihtiyaç duyulur. Örneğin bir kitap seçilmek istenildiğinde, bu kitabın hangi kitap
olacağı öyle bir anlatılabilmeli ki, başka hiçbir kitap ile karışmamalıdır. Bunu yapmanın tek
yolu, bir alanı birincil anahtar alan olarak belirlemektir. Anahtar alan seçilirken, kısıtlamadığı
sürece, doğal alanlar seçilmeye dikkat edilmelidir. Örneğin araçlar ile ilgili bir tablo
yapılırken, plakalar anahtar alan olarak belirlenebilir. Çünkü her bir plakadan bir tek araç
trafiğe çıkabilir ve plakalar kısıtlamaz.
Nesnelerin Her Bir Özelliği İçin Tabloya Bir Sütun Eklenmesi
Tablo adları tanımlandıktan ve anahtar adları belirlendikten sonra, tablolara sırasıyla adını
veren nesnelerin her bir özelliği için bir alan (sütun) eklenir. Örneğin,
Kitap için; Kitap no, ISBN no, kitap adı, yazarı, türü, sayfa sayısı, özeti, fiyatı, baskı yılı vb.
Üye için; UyeNo, adı, soyadı, e-mail adresi, ev telefonu, cep telefonu, iş telefonu vb.
Personel için; Personel sicil No, adı, soyadı, e-mail adresi, mesleği, çalıştığı birim, maaş vb.
Bu hazırlıklar yapılırken yapılması istenilen proje ile ilgili basılı formlar vs. varsa, onların
incelenmesi tabloya eklenecek sütunların hangi özellikler olması gerektiği konusunda karar
verilmesinde yardımcı olurlar.
En başa birincil anahtar olarak belirlenen alanı eklemek bir kural değildir ancak tablonun
anlaşılırlığı ve göze hoş görünmesi açısından tercih edilmesi faydalı olacak bir tekniktir.
Genellikle, yapay birincil anahtar alanlar tablo adı ile başlar ve sonunda ID vardır. Ogrenci
tablosu için ogrenciID, Personel tablosu için personelID gibi.
Tekrarlayan Nesne Özellikleri İçin Ek Tablolar Oluşturması
Akılda hep şu soru olmalıdır: veri tekrarı olacak mı? Veri tekrarı olacaksa bir yerlerde hata
yapılıyor demektir. Bu durumda eldeki tablonun en az bir tabloya daha ayrılması gerekiyor
demektir. Şu da unutulmamalıdır, her projeye uyacak evrensel bir veri tabanı tasarım tekniği
yoktur. Yani her şey belli kurallar çerçevesinde ne kadar detayıyla düşünülüp tasarlandığına
bağlıdır. Örneğin, her bir kitap için tür belirledik ama bir kitap hem kişisel gelişim
kategorisine hem de hikâye kategorisine girebilir. Veya bir kitap birden fazla kişi tarafından
yazılmış olabilir. Bir kitap için birden fazla türü kaydedebilme ele alınsın: Bu türden bir
sorunu çözmek için ilk akla gelen şey, Kitap tablosunda tür alanı için 2.sütun daha eklemek
olabilir. Bu tabloya 2.Tür ve 3.Tür diye iki sütun alanı daha eklemek. Ama çoğu kitap bir tek
türdendir ve bu kitap için eklenen 2 alan hep boş kalacaktır. Öte yandan, 4.türe birden giren
Sayfa 12
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
bir kitap olduğunda 4.tür bilgisi nereye yazılacaktır? Aynı alana mı? Ya da dört adet bölüm
mü açılacak? Bunlar, veri tabanı tasarımının doğasına terstir. Diğer çözüm yolu ise, bir kitabı
iki kere kaydedip, birincisini, ‘Kişisel Gelişim’ türü olarak; ikincisini de ‘Hikaye’ olarak
girmektir. Bu durumda tabloda aynı kitaba ait iki kayıt olacaktır ve kitap türü dışındaki diğer
tüm bilgiler tekrar edecektir. Ya da bir süre sonra, kitap hakkında girilen bilgilerin yanlış
olduğu fark edilecektir. Hangi kayıt güncellenecektir? Ya biri düzeltip diğeri unutulursa?
Sonuçta veri tekrarı ve veri bütünlüğünün bozulması söz konusudur. Bu da yine ilişkisel veri
tabanı tasarımının doğasına terstir. Bu durumda, türler diye bir yeni tablo oluşturup, bir de
kitap_turler diye 2.tablo’yu oluşturduktan sonra bu türden bilgileri burada tutmak
gerekecektir. Böylelikle, hiçbir türde yer almayan kitaptan 10 ayrı türde yer alan kitaba kadar
bütün olasılıklar için bir çözüm geliştirilmiş olur.
Anahtar Alana Bağlı Olmayan Alanların Belirlenmesi
İlişkisel veri tabanında, tablodan herhangi bir tek kayda erişmek için mutlaka bir farklı özellik
sağlanmalıdır ve bu özellik de anahtar alan tarafından sağlanır. Ancak bazen, anahtar alan ile
aynı satırda yer aldığı halde, anahtar alan ile birebir ilişkisi olmayan bir alan yer alabilir. Bu
türden alanların elimine edilip ayrı tablolara ayrılması gerekir. Örneğin, ödünç tablosu ele
alınacak olursa, ödünç verilen her kitap için ödünç alanın adresi de bilinmek istenirse, bu
ödünç tablosuna yazılamaz. Çünkü ödünç tablosunun birincil anahtar alanı oduncno’dur ve
bu alan, ödünç verme işlemi ile ilgilidir. Oysa ödünç alanın adresi, ödünç alan kişinin
kendisine bağlı bir özelliktir. Bu kişinin her aldığı kitap için adresini tekrar yazmaya gerek
yoktur. Aynı şekilde otomasyon içerisinde başka yerlerde de bu kişinin adres bilgilerine
muhtemelen ihtiyaç duyulabilir çünkü adres, üyenin bir özelliğidir. Ödünç verilen kitabın
adresi öğrenilmek istenildiğinde, üyeler adında bir tablo daha açılıp, burada herkesin adres
bilgisi tutulmak zorunda kalınır. Ödünç tablosunun ise, oduncAlan bilgisi olarak, Üyeler
tablosunun birincil anahtar alanına bir bağlantı (yabancı anahtar) içermesi daha doğru olur.
Tablolar Arasındaki İlişkiler Tanımlanması
Tanımlanan tablolardaki alanların birbirleriyle olan ilişkileri tanımlanır. Örneğin öğrenci
bilgilerinin tanımlandığı tablo ile öğrenci notlarının tanımlandığı tablo arasında bir ilişki
kurulur ve bu ilişki öğrenci numarası ile olur. Öğrencinin hangi dersine ait not bilgisi
yazılacaksa ders kodları ve adlarının tanımlandığı tablo ile öğrenci notları tablosu arasında bir
ilişki vardır. Bu ilişki notlar tablosundaki ders kodu ile ders kodları tablosundaki dersin kodu
alanları arasında yapılır. İlişki her iki tablo bir birincil alan ve bir yabancı anahtar alan
üstünden birbirine bağlanır. Bu ilişkiler MS SQL Server, MS Access veya Oracle
veritabanlarında şematik olarak hazırlanabilir.
Farklı tablolardaki iki alan aynı veriyi tutuyorsa iki alana da aynı ismi vermek karışıklığa yol
açabilir gibi görünse de aslında daha düzgün bir yapının ortaya çıkmasını sağlar. OgrenciNo
alanı örgenci tablosunda da notlar tablosunda da öğrenci numarası olarak tanımlanabilir. Bu
alanlardan birine OgrenciNo, diğerine NotlarOgrenciNo ismi verilmesi sorgu ve program
yazılımında isim karışıklıklarına neden olabilir. En önemlisi de her alan için her tabloda farklı
isimlerin kullanılması değişkenlerin isimlerinin akılda tutulmasını ve daha sonraki tablolar
üzerinde işlem yaparken işlemleri zorlaştırır. Tablo ve alanları kullanılacağı zaman her
Sayfa 13
YÖNETİM BİLİŞİM SİSTEMLERİ
7. Hafta Ders Notu
seferinde ilgili alanın hangi isimle kaydedildiğine bir listeden bakmak zorunda kalınır. Çünkü
büyük bir veri tabanı projesinde 250’den fazla tablo bulunabilir. Her tabloda da birçok alanın
bulunacağı dikkate alındığında her alana ait isimlerin akılda tutulması mümkün
olmamaktadır. Birden fazla tabloda olan alanlar için; aynı ismi kullanmak bu zorluğu ortadan
kaldıracaktır. En mantıklısı her ikisine de Ogrencino ismi verilmesidir.
Veri Tabanı Normalizasyonu
Bir tablo içerisinde yer alacak kaydın nelerden oluşmasına karar vermeye yarayan
düzenlemelere normalizasyon kuralları denilir. Bu kurallar ilişkisel veri tabanı tasarımından
başlı başına bir işlemdir. Normalizasyon, veri tabanı tasarım aşamasında çok önemli bir
işlemdir. Normalizasyon arttıkça tablolar arasındaki ilişkiler artar. Bu nedenle tablodaki
veriler erişmek için gerekli bağlantıların sayısı da artar.
Veri Ambarı
Veri ambarı; bir işletmenin ya da kuruluşun değişik birimleri tarafından canlı sistemler aracılığı
ile toplanan bilgilerin, gelecekte kullanılabilecek ya da değerlendirilebilecek olanlarının arka
planda üst üste yığılarak birleştirilmesinden oluşan büyük çaplı bir veri deposudur. Ürün
değil, ortamdır.
Datamart; veri ambarının alt kümesidir, küçük boyutludur. Metadata; veri ambarında verilerin
tanımlandığı kısımdır.
Veri Ambarının Kullanım Amaçları
Müşterilerin gizli kalmış satın alma eğilimlerini tespit etmek
Satış analizi ve trendler üzerine odaklanmak
Finansal analizler yapmak
Stratejik Analiz (Bir karar destek sistemi olmasından dolayı)
Veri Ambarı Fonksiyonları
Değişik platformlar üzerindeki işletimsel uygulamalara ait verilere erişim ve gerekli
verilerin bu platformlardan alınması
Alınan verilerin temizlenmesi, tutarlı duruma getirilmesi, özetlenmesi, birleştirme ve
birbirleriyle entegrasyonunun sağlanması
Dönüştürülen verilerin veri ambarı veya datamart ortamına dağıtımı
Gönderilen verilerin bir veri tabanında toplanması
Depolanan bilgi ile metadatada bulunan ilgili bilgilerin veri katalogunda saklanması ve
son kullanıcılara sunulması
Veri ambarı veya datamartta bulunan bilgileri uç kullanıcıların karar destek amaçlı
kullanımının sağlanması
Sayfa 14