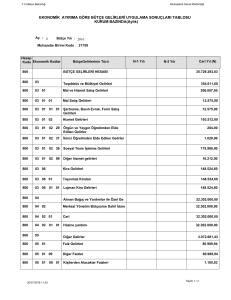
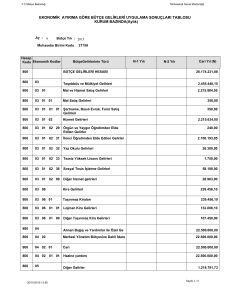
A[0….n-1]
advertisement

ALGORİTMA ANALİZİ Algoritmayı analiz ettiğimizde; Biz algoritmanın problemi uygun şekilde çözdüğünü göstermeliyiz. Sonra, algoritma problemi nasıl verimli biçimde çizilebilir Algoritmayı analiz etme çalışma zamanı miktarına karar vermektir. Bu zaman saat zamanı değildir. Daha ziyade algoritmayı gerçekleştiren yaklaşık çalışma miktarıdır. Çalışma zamanı ile ilgili olduğundan bazen zaman kelimesi kullanılacak. Biz özel problemleri çözen algoritmaların verimliliği ile ilgileniyoruz. Çünkü algoritmanın saat zamanına bağlı hızı bilgisayar donanımı ile ilgilidir. Analiz bir denklem oluşturacak her giriş için uygun olan. Bu oluşturulan denklemlerin büyüme hızlarını karşılaştıracağız. Denklem büyüme hızları kritiktir. Çünkü giriş boyutu küçük olduğunda A algoritması B algoritmasından daha az işlem yapabilir fakat giriş boyutu büyüdüğünde daha fazla yapabilir. Genel olarak algoritmalar; hem öz yinelemeli hem de tekrarlı olarak sınıflandırılabilir. Repetitive (Tekrarlı) Algoritmalar Temelde; Döngüler (loops) ve Şartlardır. Bu yüzden analiz döngülerin durumuna bağlıdır. Recursive (Özyinelemeli) Algoritmalar Büyük problemleri parçalara ayırarak çözer. Sonra her bir parçaya algoritmayı uygular. Bunlar divide and conquer algoritmaları olarak da söylenir. Büyük problemleri küçük parçalara ayırarak çözme kolay olan algoritma üretir. Yinelemeli (recursive) algoritmayı analiz etme küçük parçaları oluşturan iş miktarını hesaplamayı ve tüm probleme çözüm getiren hesaplamayı gerektirir. Biz küçük parçalar ile onların boyutlarını birleştirerek algoritmanın tekrarlama ilişkisini üretebiliriz. Bu tekrarlama diğer denklemler ile karşılaştırılabilen kapalı bir forma dönüştürülebilir. Biz ilk haftalarda: Analizi ve neden yaptığımızı anlatacağız. Biz hangi işlemleri yapacağız ve hangi analiz kategorilerinde yapacağız Birkaç matematiksel kavram inceleyeceğiz. Analiz Nedir? Algoritma analizi N tane input değer kümesine sahip bir problem için ne kadar ……… alır. Bunu tahmin etmemizi sağlar. Örneğin; küçükten büyüğe N değerli bir listeyi sıralamak için ne kadar karşılaştırma yapılacağı kararını vermek için veya N*N boyutunda iki matris çarpımının ne kadar aritmetik operasyon gerektirir. Algoritma analizi algoritmalar arasından seçim yapmamızı sağlar. Örneğin; 4 sayıdan en büyüğünü bulan iki farlı algoritma düşünelim. Algoritma 1 largest=a; if b>largest then largest=b endif if c>largest then largest=c endif if d>largest then largest=d endif return largest Algoritma 2 if a>b then if a>c then if a>d then return a else return b endif else if c>d then return c else return d endif endif else if b>c then if b>d then return b else return d endif else if c>d then return c else return d endif endif endif Her birinde en az 3 karşılaştırma vardır. İlki kolay anlaşılmasına rağmen Bilgisayar için ikisi de aynı karmaşıklığa sahiptir. Zaman açısından iki algoritma da aynıdır. Boşluk açısından ilkinde daha fazla alan gerekli çünkü largest geçici değişkenini çağırmış. Eğer biz karakter veya sayı karşılaştırıyorsak bu boşluk önemsizdir. Ama diğer data tiplerinde önemli olabilir. Çoğu modern programlama dilinde karşılaştırma operatörleri büyük ve karmaşık nesne ve kayıtlar için tanımlanır. Bunun için boşluk oldukça önemlidir. Biz algoritma verimliliği ile ilgilendiğimizden öncelikli olarak zaman konusuyla ilgileneceğiz. Boşluk söz konusu olduğunda onu tartışacağız. Bizim amacımız bir problemi çözen iki farklı algoritmayı karşılaştırmaktır. Bunun için asla örneğin sıralama ile matris çarpım algoritmaları gibi iki farklı algoritmayı karşılaştırmayacağız. Algoritma analizinin amacı özel bir algoritmanın ne kadar saniye ya da çevrim sürdüğü ile ilgili formül ortaya koymak değildir. Bu bilgi kullanışlı olmaz çünkü durumdan bilgisayar kaynaklarının performansıyla ilgilenmek zorunda kalırız. Daha hızlı donanıma sahip bilgisayar algoritmayı daha hızlı geçekleştirebilir. Bizim analizimiz herhangi özel bir bilgisayardan bağımsızdır. N’in bir fonksiyonu olarak küçük ve basit rutinlerde operasyonun tam sayılarını saymamız mümkündür. Çoğu zaman kullanışlı değildir. İleride N+5 operasyon ile N+250 operasyon arasındaki farkları anlamsız olduğunu göstereceğiz. Nedeni N çok büyüktür. İki bölümde tam sayıları sayacağız. Biz ilk 16 counter’a sıfır atadık ve diğer counter’ları 15 kez kopyaladık. Bu durum başlangıçta 33 durum kontrolü, 33 atama ve 31 artırımı düşürür. Giriş operasyon 770’den 97’ye düşer. Bu da %87 azaltımdır. 50000 karakterde %0.7’den daha az kurtarma olur. Görülüyor ki eğer döngüsüz başlangıç işlemi yaparsak daha fazla zaman kazanıyoruz. Çünkü 31 temel atama işlemi oluyor. %0.07 tasarruftur. Görülüyor ki başlangıç işlemlerinin tüm algoritma çalışmasıyla küçük ilişkisi vardır. İnput değerleri arttığında başlangıç sayısı anlamsız oluyor. İlk algoritma analizi Turing makinesi hesaplamasıdır. Algoritmalar ortak kontrol yapılarına sahip olduğu sürece özellikler önemsiz. Bunun anlamı bir döngü mekanizması her dilde, bunlar; for, while, if, case, switch bizim ihtiyaçlarımıza hizmet edecek. Biz bir seferde bir algoritma ile ilgileneceğimi için, biz nadirenbir fonksiyon ya da kod bölümüyle ilgileneceğiz ve bu yüzden dilin gücünden önemli olmayacak. Bu yüzden biz psuedo code kullanacağız. Bazı diller short- circuit değerlendirme kullanır. Örneğin A true ise değerlendirilir. A false ise B değerlendirilir. Bu kadar karşılaştırma önemli olmayacağı için biz önemsemeyeceğiz. Biz her operasyon için hesap yapmayacağız. Örneğin: Bir dosyadaki farklı karakterleri sayan algoritmada for all 256 characters do assign zer oto the counter end for while there are more characters in the file do get the next charactere increment the counter fort his character by one end while (Bu kod en az 256+1 atama, 256 artırma, 258 kontrol yapar) Algoritmaya baktığımızda 256 karakter için giriş yapılmıştır. Eğer giriş dosyasında N karakter varsa ikinci döngü için N geçiş vardır. Soru şu biz ne kadar sayacağız? For döngüsünde, döngü değişkenine sahibiz ve döngünün her geçiş için döngü değişken sınırları içinde olduğunu, döngünün icrası ve döngü değişkeninin artışı kontrol edilir. Bunun anlamı 257 atama vardır(1 atama döngü değişkeni, 256 atama counter için), döngü değşkeni 256 artırım ve döngü sınırları içinde 257 kontrol yapar(1 kontrol döngü durduğunda yapılır). İkinci döngü için N+1 kez durumun kontrolünü yaparız ve N counter’ını artıracağız. Toplan operasyon sayısı Artırım N+256 Atama 257 Durum kontrolü N +258 Bu yüzden eğer dosyada 500 karaktere sahipse algoritma 771 başlangıca sahip olan 1771 operasyon yapacak. Bu %43 demektir. Eğer 50000 karaktere sahip olsa 770 başlangıca sahip olan 100,771 operasyon demektir. Ama bu %1’den daha az başlangıçtır. Başlangıç değişmiyor N arttıkça daha küçük yüzdeye sahip oluyor. Diğer bakış açısıyla bilgisayar organizasyonunda hatırlatacağımız kadarıyla büyük bir veri bloğunun kopyalanması bir atama kadar hıza sahiptir. 1.1.2.Boşluk Karmaşıklığı Bir bilgisayardaki depolama alanı sınırılı olduğu için boşluk karmaşıklık analizi önemlidir. Algoritmalar ekstra boşluk ihtiyacı bulunanlara bölünür. Programcı eğer hızlı algoritma ekstra boşluk istiyorsa yavaş algoritma kullanabilir. Bilgisayar belleği önemli bir unsurdur. Eğer datayı depolamak için daha verimli yollar varsa başka boşluk analiz formaları sınanmalıdır. Örneğin: Biz -10 ile +10 arasında ve ondalık noktalı ve hassas bir yere sahip olan gerçek bir sayı depoluyoruz. Eğer biz bu sayıyı depolarsak çoğu bilgisayar hafızada 4 byte ve 8 byte kullanacak. Fakat 10 ile çarparsak, -100 ile +100 arasında bir integer olarak depolayacağız. Bu 1 byte ihtiyaç duyar ve biz 3 veya 7 byte tasarruf ederiz. Bu değerlerin 1000 saklayan bir program 3000 ve 7000 arasında tasarruf eder. Bilgisayarlar 1980’de 65.536 memoriye sahipti ve bu boşluk çok önemliydi. Tarihleri tutan bir program yazdığında 1999 yerine 99 olarak depolayarak boşlukların yarısını kullanabilirsiniz. Bugün bu boşluk analizinin kullanılmadığını görebilmekteyiz. Çünkü müşteriler rahatlıkla yeni bellek alabilmektedir. Giriş Sınıfları İnput analizi algoritmalarda önemli rol oynar. Çünkü bir algoritmanın hangi icra yollarını kullanacağına karar veren inputtur. Örneğin n sayı içinden en büyük değeri bulalım. Algoritmamız: largest =list[1] for i=2 to N do if(list[i]>largest) then largest=list[i] end if end for Eğer liste azalan sırada ise döngüden önce bir atama yapılacak. Eğer liste artan sırada ise N atama olacak(döngüden önce 1, döngü içinde N-1) Biz bu analizi mümkün olan tüm kümeler için düşünmeliyiz. Kümeler N sayıdan da oluşabilir. Bu durum algoritmanın hızını etkiler. Biz input bakarken, input farklı input kümelerine ayıracağız. Bu analiz işini kolaylaştıracak. Örnek: 10 farklı sayıdan en büyüğünü buluyorsak burada 10! İşlem var veya bu sayıları düzenlemek için 3.628.800 yol var demektir. Eğer en büyük sayı ilk sayı ise bir atama yapılır. Bu yüzden 362.880 input kümesi alırız. Eğer ikinci en büyük sayı ise 2 atama yapılır. Başka bir 362,880 input kümesi vardır. Algoritmaya baktığımızda 1 ile N arasında atama olacak. Bu yüzden atama yapılacak sayılar üzerinden N farklı sınıf oluşacak. Düşünülen ve Hesaplanan Durumlar 2 adımda sayma yapacağız. 1. Önemli operasyonları seçiyoruz. 2. Bu operasyonlardan hangisi algoritmanın ayrılmaz bir parçasıdır karar veriyoruz. Önemli operasyonların 2 sınıfı vardır. Karşılaştırma ve aritmetik Karşılaştırma operatörleri arama ve sıralama gibi algoritmalarında hesaplanır ve tüm eşdeğerlikleri düşünülür. Çünkü bu tip algoritmalarda bir şey arandığında ya da sıralandığında önemli olan karşılaştırmadır. Karşılaştırma operasyonları eşit, eşit değil, büyük, küçük, büyük eşit, küçük eşiti içerir. Biz toplamada ve çarpmada aritmetik operatörleri inceleyeceğiz. Toplam operatörleri: Toplama çıkarma artırma ve azaltma Çarpım operatörleri: Çarpma bölme ve modül İki grup ayrı hesaplanır çünkü çarpma toplamadan uzundur. Her ne kadar toplam sayısını arttırsa bile çarpım sayısını azaltan algoritmalar daha uygun görülür. Bizim anlatacaklarımızın dışında logaritma ve geometrik fonksiyonları bilgisayar daha sıklıkla hesaplar ve çok zaman tüketir. Özel bir durum olarak 2 ile çarpma ve bölme toplamı kadar hızlı olarak düşünülen kayma problemini azaltır(shift operations). Divide- conquer algoritmalarında 2’ye bölme ve çarpma sık kullanılır. Durumlar Bir algoritma analiz edilirken hangi input kümesinin kullanıldığı algoritmanın gerçekleşmesinde önemli etki oluşturur. Eğer sıralı bir giriş seti geldiğinde bazı algoritmalar çok iyiyken bazıları kötüdür. Tam tersi, rasgele bir veri seti geldiğinde geçerlidir. Bundan dolayı biz analiz yaparken bir input setine bağlı kalmayacağız. Bir algoritma bazı input setlerine çok hızlıyken bazılarında çok yavaş olabilir. Bu yüzden ortalama performansı temel alacağız. En İyi Durum (Best Case) Adından da anlaşılacağı gibi bir algoritmanın en kısa zamanda tamamladığı input kümesidir. Bu giriş algoritmaya en az miktarda iş yaptıran değerler kombinasyonudur. Eğer searching(arama) algoritmasıyla aranan değer algoritmanın ilk baktığı yerdeyse bu en iyi durumu oluşturacak. Algoritma karmaşık olsa da bu durum bir karşılaştırma gerektirecek. Liste ne kadar büyük olursa olsun arama 1 sabit zamanda gerçekleşecek. Çünkü algoritmanın en iyi durumu çok küçük ve sabit değerdir. Biz en iyi durum analizini sık yapmayacağız. En Kötü Durum (Worst Case) Önemli analizdir. Çünkü algoritmanın alacağı en çok zamanı verir. En çok çalışmaya neden olan input değerlerini tanımlarız. Arama algoritmaları için listenin en sonunda olan veya listede olmayan durumlar en kötü durumdur. Listedeki her değerle karşılaştırma yapılacağından N karşılaştırma yapılır. En kötü durum bize algoritmayı yavaşlatabilecek en üst sınırı verir. Ortalama Durum (Avarage Case) Ortalama durum, algoritmanın en dayanıklı durumudur. Çünkü içinde detayların çoğunu barındırır. Temel süreç mümkün olan tüm input kümelere farklı gruplara bölünerek başlar. İkinci adımda her gruptan gelecek input için algoritma ne kadar çalışır karar verilecek. Her gruptan inputlar aynı zamanda alınmalı, eğer olmuyorsa grup iki ayrı gruba bölünmelidir. Tüm bunlar yapıldığında aşağıdaki formül ortaya çıkar. n, input boyutu, m grup sayısı, pi olasılık, input grup i den olacak ve ti grup i’den input alma zamanı. Bazı durumlarda, biz her input grubunun eşit olasılığa sahip olduğunu düşüneceğiz. Yani, input gönderirken grup 1 ile grup 2 aynı şana sahip olacak. Eğer 5 grup varsa tüm olasılık 0,2 olacak. Biz aşağıdaki formüle göre olasılığı hesaplayacağız. Arama algoritması Diğer formül P olasılık 0<P<=1 arası Pozisyon i Listede i. Pozisyonla karşılaşma olasılığı P/n Karşılaştırma başarısızsa n durum olacak [1-P] ile C(n)= p/n[1+2+3+…+n]+n(1-p) = p/n.(n.(n+1))/2+n(1-p)=p(n+1)/2+n(1-p) genel formül P=1 için (n+1)/2 P=0 için n Matematik altyapısı Birkaç matematik kavramı kullanacağız 1. Taban(floor) ve tavan(ceiling) sayılar Gösterilişi floor[x] veya ceiling[x] sayı için en küçük ve en büyük tam sayı değeri x=2 için floor[x]=2 ceiling[x]=2 x=2.4 için floor[x]=2 ceiling[x]=3 x=2.9 için floor[x]=2 ceiling[x]=3 x=-3.3 için floor[x]=2 ceiling[x]=-3 biz bu sayılara bir şeylerin kaç kez yapıldığına karar vermek için ihtiyaç duyarız. Değer bazen virgülden sonraki(fractional) kısma bağlı olur. Örnek: eğer N değerli bir kümede biz 1 ile 2 yi 3 ile 4 ve devamını karşılaştırıyorsak Karşılaştırma sayısı [N/2] olacak. N=10 ise [10/2]=[5]=5 Eğer N=11 ise [11/2]= [5.5]=5 karşılaştırma olacak Diğer bir kavram faktöriyeldir. Logaritma Analizde logaritma önemli rol oynar. Logaritma Y tabanında x x’i üretecek y demektir. Bu yüzden log1045 1,653 çünkü 101,653=45’dir. Biz logaritmayı 10 tabanında ve 2 tabanında kullanacağız. Logaritma tam anlamıyla artan fonkdiyondur. Bunun anlamı x ve y sayıları Eğer x>y ise; logbX > logbY dir. Logaritma bire bir fonksiyondur. loga A.B= loga A+ loga B logbX = logbY ise X=Y olur. logB1=0 logB B=1 logB (X,Y)= logB X + logB Y logB Xy = Y. logB X logA X= logB X / logB A loga d= loga b. logb c. logc d Binary Trees Binary Tree biz yapıdır. Ağaçtaki her düğüm en fazla iki düğüme sahip olurlar. Her düğüm üst düğümdür. En üst düğümün ailesi yoktur ve kök olarak çağırılır. N düğüme sahip binary tree eğer sıkıca yerleştirilmişse [logN]+1 seviyeye sahiptir. Örnek: 15 düğümlü bir binary tree bir kök ve 2. Seviyede 2 düğüme, 3. Seviyede 4, 4. Seviyede 8 düğüme sahiptir. Denklem [log15]+1=[3,9]+1=4 Eğer bir düğüm daha eklersek [log16]+1= [4]+1=5 ve yeni seviye olur. N düğüme sahip binary tree ağacı eğer her düğümün bir alt düğümü olursa N seviyeye sahip olur. Eğer bir ağacın seviyelerini sayarsak level 1 kök olarak level K 2K-1 düğümden oluşur. J seviyeli tam bir binary tree ağacında 1 ya da J-1 kadar tüm seviyeler kesinlikle 2 çocukludur. Olasılık Algoritma analizi input ile ilgilidir. Bu yüzden input kümelerinin ihtimallerini değerlendirmeliyiz. Olasılık 0 ile 1 arasında olacak. 0 asla olmaz, 1 her zaman olur anlamındadır. Eğer 10 input varsa bunların her biri için 0 ve 1 arasında bir değer ardır. Bireysel olasılıkların toplamı 1’dir. Her birinin olasılığıysa 1/10’dan 0,i olur. Eğer N tane durum varsa 1/N olasılık vardır. Toplam Eğer döngülü bir algoritmaya sahipsek döngü değişkeni 5 eşit, biz 5 adım gideceğiz. Döngü değişkeni M’dir. M adım gidilir. Döngü değişkeni 1’den N tüm değerleri kapsayacağı için toplam adım 1’den N tüm değerlerin toplamı olur. Denklem Toplam Kuralları Büyüme Oranları Algoritma analizinde ne adar operasyon olduğunu bilmek önemli değildir. Daha önemlisi problemi çözme için problemin büyümesine göre algoritma için operasyonların büyüme oranı önemlidir. İnput kümelerinin ne olduğu önemli değildir. Biz genel durumla ilgilendiğimiz için algoritmanın büyümesiyle ilgileniriz. Figüre 1.1 baktığımızda x^2ye bağlı fonksiyonun başta yavaş büyürken daha sonra hızla büyüdüğünü görürüz. Grafik yorumlanabilir. Biz daha çok algoritmanın yaptığı operasyonlardan ziyade algoritmanın büyüme oranıyla ilgileneceğiz. Bir fonksiyonun boyutuyla ilgilendiğimizde, biz x’in büyük değerleriyle ile ilgileneceğiz. Algoritma sınıflarıFigure.1.2 de incelenebilir. Tabloda görüldüğü gibi bizim ilgimiz input büyüdükçe neler olduğu ile ilgilidir. Çünkü küçük input kümeleri önemli farkları gizleyebilir.1.1 ve 1.2’ de ikinci nokta. Hızlı büyüyen fonksiyonlar yavaş büyüyenleri hızlıca domine eder. Eğer algoritma karmaşıklığı bu iki sayının kombinasyonu ise biz yavaş büyüyeni ihmal edeceğiz. Örnek:𝑥 3 − 30𝑥 karşılaştırma yapıldığında 𝑥 3 referans alacağız. Çünkü 𝑥 3 𝑖𝑙𝑒 𝑥 3 − 30𝑥 arasındaki fark 100 input için %0.3’dür. Büyüme Sınıfları Bir denklemdeki en büyük terim diğerlerini domine eder. Bu yüzden biz daha yavaş büyüyen terimleri çıkartırız. Biz yavaş terimleri çıkardığımızda geri kalan kısmına algoritmanın veya fonksiyonun order olarak çağrılır. Biz algoritmaları order’ları temelinde gruplandırabiliriz. 1.En azından bazı fonksiyonlar kadar hızlı büyüyenler 2.Aynı oranda büyüyenler 3.Bir fonksiyondan daha hızlı büyüme göstermeyenler Big Omega Ω(f) big omega en fazla f fonksiyonu kadar hızlı büyüyen fonksiyonlar sınıfını temsil eder. N0 eşik değerinden daha büyük n’in tüm değerleri için Ω(f)’deki tüm fonksiyonlar en az f kadar büyük değerlere sahiptir. Ω(f) bir fonksiyonun en düşük sınırı olarak görülebilir. Çünkü bu fonksiyonların tümü f kadar hatta n’den daha hızlı büyür. Bunun anlamı Eğer g(x) ∈ Ω( f ), tüm n ≥ n0’lar için g(n) ≥ cf(n)’dir. Bizi verimlilik ilgilendirir. Ω( f ) çok fazla ilgilendirmez. Çünkü Ω( n^2), n^3 ve 2^n içeren n^2’den daha hızlı büyüyen tüm fonksiyonları içerir. Big Oh Bir fonksiyondan daha hızlı büyüme göstermeyen sınıflar big oh O(f) olarak çağırılır. n0 eşik değerinden daha büyük n değerlerinin tümü için O(f) sınıfındaki fonksiyonların tümü f fonksiyonundan daha hızlı büyümez. O(f) en yüksek sınır olarak f fonksiyonuna sahiptir. Bu yüzden bu sınıftaki fonksiyonların hiçbiri f’den daha hızlı büyümez. Bunun anlamı Eğer g(x) ∈ O( f ), tüm n ≥ n0’lar için g(n) ≥ cf(n)’dir. En çok ilgileneceğimiz sınıftır. İki algoritma düşündüğümüzde biz ikinci fonksiyonun big oh sunda birincinin olduğunu bilmek isteriz. Eğer böyleyse problem çözmek ikinci algoritma birinciden daha iyi değildir. Big Theta F fonksiyonuyla aynı oranda büyüyen fonksiyon sınıflarını θ( f) big theta olarak çağırılır. Bunun anlamı n0 eşik değerinden daha büyük tüm n değerleri için, θ( f) ’deki fonksiyonların tümü f ile aynı değere sahiptir. Big omega ile big oh’un üst üste geldiği yerler olarak tanımlanır. θ( f)= Ω( f ) n O(f) Biz algoritmaları ele aldığımızda düşündüğümüz bir algoritmadan daha iyi olan algoritmaları bulmayla ilgileneceğiz.Bu yüzden big thetadaki birini bulma bizi çok ilgilendirmez. Biz bu sınıfları çok kullanmayacağız. Big Oh Bulma Fonksiyon big oh’daysa Eğer Bunun anlamı eğer g(n)/f(n) sonsuzdan küçük gerçek bir sayıysa, g O(f) dedir. Bazı fonksiyonlar gözükmeyebilir. Bu yüzden g ve f’nin türevini alıp aynı limiti uygulayacağız. Notasyon G bu kümelerin bir elemanıdır. Çünkü θ( f),Ω( f ), O(f) kümedir. Bazı kaynaklar g=O(f) diye gösterebilir. Bunun anlamı g(x) ∈ O( f )’dir. Limit 0 ise f(n)’den daha küçük Sabit ise f(n) ile aynı Sonsuz ise f(n)’den daha hızlı Tekrarlı Algoritma Analizi Analiz için aşağıdaki sırayı takip edebiliriz. 1. İnput boyutunu belirten parametreleri tanımlama 2. Algoritmanın temel operasyonlarını belirle 3. Temel operasyonların çakışma sayının yalnızca input boyutuna bağlı olup olmadığını kontrol et. Eğer bazı ek özelliklere bağlıysa worst case, avarega case ve eğer gerekirse best case verimliliğini ayrı ayrı incelemeliyiz. 4. Algoritmanın temel çalışma sayısını ifade eden bir toplam kur. 5. Standart formül kullanarak veya toplam kullanarak hesap için en yakın formu bulma ya da en azından büyüme oranını görme Ör: Eleman eşitsizlik problemi: dizide verilen elemanlar birbirinden farklı mı değil mi kontrol eden yazılım // İnput: bir dizi A[0,1,2…n-1] //Output: Eğer A’daki tüm elemanlar farklıysa “true” değilse “false” for i 0 to n-2 do for j i+1 to n-1 do if A[i]= A[j] return false return true Burada input boyutu dizi boyutudur.(n) En iç döngü bir karşılaştırma çalıştırıyor. Bu en temel operasyondur. Elemen karşılaştırması sadece (n) bağlı değil dizide eş eleman olup olmadığına bağlıdır. Eğer varsa bizim aramamızı sadece worst case ile sınırlayacak. Cworst(n) n boyutlu tüm diziler arasından en büyüğüdür. En iç döngü iki tane worst case sahiptir. Ya hiç eş yoktur ya da dizinin en son karşılaştırılan iki elamanıdır. Formül: Algoritma n elementli bir dizide tüm farkları bulmak için n(n-1)/2 karşılaştırmaya ihtiyaç duyar en kötü durumda. Ör: A ve B nxn matris C=A.B bulalım. Satırlarla sütunlar çarpılır. C[i,j]= A[i,0]B[0,j]+………+ A[i,k]B[k,j]…………+ A[i,n-1]B[n-1,j] 0≤i, j ≤n−1. Algoritma // İnput: 2nxn matris A ve B //Output: Matris C=A.B for i 0 to n-1 do for j 0 to n-1 do c[i,j] 0,0 for k 0 to n-1 do c[i,j] c[i,j]+ A[i,k]*B[k,j] return c İç döngüde iki aritmetik işlem vardır. Çarpma ve toplama. Bu işlemlerin ikisi de bir kez yürütülür. Birini hesaplayarak diğeri de hesaplanmış olur. Özel bir makine üzerinde bu algoritmanın çalışma zamanının tahmin etmek istersek T (n)≈ Cm M(n)= Cm n3 Cm makine üzerinde çarpma zamanı daha doğru tahmin için toplama zamanını da ekleriz. T (n)≈ Cm M(n)+ Ca A(n) = Cm n3 +Ca n3=( Cm+ Ca) n3 Özyinelemeli(Recursive) Algoritma Analizi Ör: Negatif olmayan tam sayılar için F(n)=n! Hesaplayın 0!=1 n!01…..(n-1).n = (n-1)!.n n>=1 O zaman F(n)= F(n-1).n özyinelemeli olarak Algoritma // İnput: negatif olmayan tam sayılar n //Output: n! Değeri İf= n=0 return 1 Else return F(n-1)*n N’yi input kümesinin bir işaretçisi olarak düşünüyoruz. Algoritmanın temel operasyonu çarpmadır. İcra sayısı M(n) olarak gösterelim. Formül: F(n)= F(n-1).n n>0 için M(n)= M(n-1)+1 [F(n-1) hesaplamak için+ n ile F(n-1) çarpmak için] F(n-1) hesaplamak için M(n-1) çarpma yapılır ve bir fazla çarpmada n ile yapılır. Bu denklem M(n)’yi tanımlamaz. Fakat n-1’in bir fonksiyonu olarak kullanılabilir. Böyle denklemler Recursives olarak çağırılır. Yukarıdaki formülü kullanarak net formülü bulacağız. Biz tek bir çözüme karar vermek için biz initial condition(giriş durumu)’na ihtiyaç duyarız. Bu durum özyinelemeli çağrıları durduran durumdur. İf n=0 return 1 initial condition Bu çağrılar iki şey söyler 1.n=0 ken çağrılar durur. N’in en küçük değeridir. Algoritma çalıştığında M(n) 0’dır. 2. Psuedo code baktığımızda n=0 olduğunda çarpma yapılmıyor. Yani initial condition M(0)=0 [n=0 iken çağrılan durum] [n=0 iken çarpma yok] Recursive ilişkiyi kurduk M[n]=M[n-1]+1 n>0 M[0]=0 n=0 Biz burada 2 özyinelemeli tanım ile ilgileneceğiz. Birincisi faktöriyel F(n)’dir F(n)=F(n-1)n n>0 F(0)=1 İkincisi F(n) hesaplamak için ne kadar M(n) gereklidir. Recursive ilişkileri çözmek için birkaç metod mümkündür. Biz backvard substitutions(geriye yerine koyma) metodunu kullanacağız. M(n)=M(n-1)+1 [M(n-2)+1]=M(n-2)+R [M(n-3)+1]=M(n-3)+3 değişti. Buradan genel formül: M(n)= M(n+i)+i N=0 baktığımız gibi i=n durumuna da bamalıyız. M(n)=M(n-1)+1=…..=M(n-i)+i…=M(n-n)+n=n O zaman Recursive algoritmaları analiz etmek için 1. İnput boyutu için parametre belirle 2. Algoritmanın temel opsiyonunu bul 3. Aynı boyuttaki farklı girişler için temel operasyonlarının tekrarının değişip değişmediğini kontrol et. Eğer değişmişs worst, artan, best durumlarını araştır. 4. Recursive ilişki kur giriş durumuyla 5. Çözümün büyümesi sırasına göre recurrence ilişkiyi çöz. Ör: Hanoi kule puzzle: Bu puzzle’de farklı boyutlarda n diske sahibiz. Bunlar 3 çubuktan herhangi birine geçirilebilir. Önce disklerin hepsi küçükten büyüğe ilk çubukda. Hedef bunları eğer gerekliyse ikinciyi kullanarak üçüncüye taşımak. Biz bir seferde bir disk oynatabiliriz. Küçüğün üzerine büyük yerleştirmek yasaktır. n>1 diskleri çubuk 1’den çubuk 3 (çubuk 2 yardımıyla) taşımak için 1’den 2 ardışık olarak n-1 disk taşırız(çubuk 3 yardımıyla) sonra 1’den 3 en büyük diski taşırız. Sonunda 2’den 3 ardışık n-1 disk taşırız(çubuk 1 kullanarak) Eğer n=1 ise biz kaynaktan hedefe tek bir disk taşırız. N disk bizim disk boyutumuz ve algoritmanın temel operasyonu bir disk taşımadır. Taşıma sayısı M(n) ise recurrence ilişki M(n)= M(n-1)+1+M(n-1 ) n>1 Giriş durumu M(1)=1 ilişkiler M(n)=2M(n-1)+1 n>1 M(1)=1 Geriye yer değiştirme yaparsak N’in ortalama bir değeri için bile çok uzun zaman çalışacak bir üsse (algoritmaya) sahibiz. Özyinelemeli algoritmaların kısa olması verimsizliğini gizleyebilir. Recursive algoritma kendine birden fazla çağrı yaptığında recursice çağrılar ağacı yapma kullanışlı olabilir. Bu ağaçta düğümler recursive çağrıları temsil eder ve biz onları çağrıların parametre değerleriyle etiketleriz. Örnekteki Hanoi kulesi için ağaç aşağıdaki gibidir. Hanoi toplam çağrıları Böl ve Yönet (divide- conquer) Bilinen en genel algoritma dizayn tekniğidir. Böl ve yönet algoritma planı: 1. Problem aynı tipte alt problemlere bölünür. 2. Alt problemler çözülür. 3. Eğer gerekliyse alt problemler birleştirilir. Diyagram olarak: Örn: n sayı toplama problemi a0,...,a n−1 Eğer n>1 ise biz problemi 2’ye böleriz. İlki[n/2] toplamı hesapama diğeri [n/2] toplamı hesaplama Bu iki toplamın her birini aynı metodu kullanarak hesaplamak için: Böl- yönet paralel hesaplama için uygundur. Çünkü her processe bir alt problemi çözebilir. Tipik olarak böl yönet algoritmaları n boyutu b alt boyuta böler. Yani n/b alt boyut oluşur. A alt elemandan oluşur. Çalışma zamanı T(n) aynı zaman n b’nin bir kuvvetidir. T(n)=a.T(n/b)+f(n) Çünkü b her zaman 2’nin üssü şeklindedir. F(n) n boyutlu bir örneği bölmek ve ya birleştirmek için harcanan zaman için hesaplanan fonksiyondur. (a=b=2 ise f(n)=1) T(n) a ve b sabit değerlerine ve f(n) fonksiyonunun büyümesine bağlıdır. Master Teorem Eğer: Benzer sonuçlar O ve Ω için de geçerlidir. Örn: n sayının toplamında A(n) toplam olsun. n=2k input boyutu k=alta inme sayısı n=20 =1 kendisi n=21 =2 ikiye bölünmüş A(n)=2.A(n/2)+1 --> f(n) (buradaki 2 a’dır. n/2deki 2 b’dir. n0’daki 0 da d dir.) F(n)= bölme ve birleştirme A=2 b=2 d=0 a>b d 2>20 2>1 A(n)∈ θ (nlogb a)= θ (nlog2 2)= θ (n) Merge Sort Böl- yönet yönteminin en mükemmel örneğidir. A[0….n-1] A[0…[n/2]-1] ve A[[n/2]….n-1] bölerek sırasıyla çözer ve sonra ikisini birleştirir. Algoritma: Merge sort(A[0…..n-1]) //sıralama A[0….n-1] //input: A[0….n-1] dizisi //output: A[0….n-1] azalmayan sırada sıralama İki sıralı diziyi birleştirelim. 2 işaretçi birleştirilecek dizilerin ilk elemanlarını gösterir. Gösterilen bu elemanlar karşılaştırılır. Ve küçük olan yeni diziye eklenir. Sonra küçük elemanın indisi artırılır. Bu işlem iki diziden biri bitene kadar devam eder. Sonra kalan elemanlar yeni dizinin sonuna kopyalanır. Algoritma Merge(B[0..p−1],C[0..q −1],A[0..p+q −1]) // bir dizide birleştirme // input: diziler sıralanmış B ve C // output: Sıralanmış A i ←0; j ←0; k←0 while i<p and j<q do if B[i]≤C[j] A[k]←B[i]; i ←i +1 else A[k]←C[j]; j ←j +1 k←k+1 if i =p copy C[j..q −1] to A[k..p+q −1] else copy B[i..p−1]to A[k..p+q −1] 8, 3, 2, 9, 7, 1, 5,4 sayılır. Verimliliği N 2’nin bir kuvvetidir. C(n) karşılaştırma sayısı. C(n)= 2C(n/2)+Cmerge(n) n>1 C(1)=0 Cmerge(n) analiz ettiğimiz karşılaştırmalar birleştirme boyunca gerçekleşir. Her adımda kesinlikle bir karşılaştırma var. Worst case de, bir dizi sadece 1 eleman içermeden hiçbir dizi boş olamaz. Bu yüzden worst case için; Cmerge(n)=n-1 Cworst(n)=2Cworst(n/2)+n−1 for n>1,Cworst(1)=0 Master teoreme göre a=bd ise θ (nd log n) 2=21 ise θ (n1 log n)= θ (nlog n) Cworst(n)∈ θ (nlog n) n=2k ‘dır. Cworst(n)=n log2 n−n+1. Örn: T (n)=4T (n/2)+n, T (1)=1 a=4 b=2 d=1 4>21 ise θ (n1 log n) T (n)=4T (n/2)+n3 a=4 b=2 d=3 4<23 θ(n3) Quik Sort (Hızlı Sıralama) Divide Conquer(Böl- Yönet) için önemli bir algoritmadır. Sıralama yaparken dizi sırasına değil dizi içindeki verilere göre sıralama yapar. Dizi içinden bir veri seçilir A[s] bu verinin soluna daha az değere sahip olanlar, bu verinin sağına daha az değere sahip olanlar yerleştirilir. Tüm veriler sıraya sokulana kadar bu süreç daha küçük parçalara bölünerek devam eder. A[0]….A[s-1] bu ifade <=A[s], A[s] A[s-1]….A[n-1] bu ifade A[s]<= Algoritma Quiksort A[l..r] //İnput A[0..n−1] bir alt dizi ve bu dizi için sol l, sağ r ile tanımlandı. //Output Alt dizi A[l..r] artan sırada sırala // if l<r s ←Partition(A[l..r]) Quicksort(A[l..s −1]) Quicksort(A[s +1..r]) Elemanlar içinden pivot olarak seçeriz bu seçim farklı şekillerde olabilir. Biz ilk elemanı pivot olarak seçeceğiz. P=A[l] bu pivot ile diğer elemanlarla karşılaştırılır. Pivotun solunda küçük sağında büyük sayılar oluşacak şekilde karşılaştırmalar yapılır. İ indisi pivot ile karşılaştırılıp pivottan büyük değer bulana kadar ilerler. Değer bulunca j indisi ilerlemeye başlar. Küçük değer bulunca durur ve i ile j’nin değerleri değiştirilir. J=i olana kadar devam eder. Bu yaklaşım Hoare algoritmasıdır. Hoare partition(A[l…r]) //ilk eleman pivot //input: A[0..n-1] sol ve sağ l ve r (l<r) //output: A[l..r] sırası p←A[l] i ←l; j ←r +1 repeat repeat i ←i +1until A[i]≥p repeat j ←j −1until A[j]≤p swap(A[i],A [j]) until i ≥j swap(A[i],A [j]) //undo last swap when i ≥j swap (A[l],A [j]) return j En iyi durum ilişkileri Cbest(n)=2Cbest(n/2)+n for n>1,C best(1)=0 Master teoreme göre Cbest(n)=n log2 n. Yani n=2k A=2 b=2 d=1 a>bd Q(ndlogn)= Q(n1logn) En kötü durum ilişkileri 8 adet sayının olduğu bir durumda N+1 karşılaştırma yapılacak. Her seferinde pivot çıkarılarak karşılaştırma yapılır. A=2 b=2 d=2 2<22 Q(n2) Ortalama durum Pivot pozisyon 0<=s<=n-1 arasındadır. N+1 karşılaştırma olacak ve her seferinde n-1-s elemana sahip olacağız. Her durum eş olasılığa sahiptir. Çözüm çok uzun Cavg(n)≈2n ln n≈1.39n log2n Bu demektir ki %39 daha fazla karşılaştırma yapılacak en iyi durumdur. Brute Force Sıralama Algoritmaları(Kaba Kuvvet) Adından da anlaşılacağı gibi başarısını bilgisayarın gücüne bağlayan çok zeki olmayan algoritma türüdür. Selection Sort Listedeki en küçük elemanı bulmak için listeyi baştan sona tarıyoruz. Sonra geriye kalan n-1 sıradan en küçüğü bulmak için listeyi tarıyoruz. Bulunca da 2. Elemanla takas ediyoruz. 0’dan n-2 taranır ve ni eleman yer değiştirir. Algoritma Selection Sort (A[0…n-1]) //input: A[0..n−1] dizi //Output: Artan sırada A[0..n−1] for i ←0 to n−2 do min←i for j ←i +1to n−1 do if A[j]<A [min] min←jswap A[i]and A[min] Bubble Sort n-1 sıradan oluşan listeyi sıralamak için i 0<=i<=n-2 Algoritm Bubble Sort [0…n-1] //input: A[0..n−1] dizisi //Output: Artan sırada A[0..n−1] for i ←0 to n−2 do for j ←0 to n−2−i do if A[j +1]<A [j] swap A[j]and A[j +1] Decrease and Conquer(Azalt Yönet) Sıralama Algoritmaları İnsertion Sort Algoritmda dizinin 2. Elemanından başlayarak elemanlar sırayla kontrol edilir. Kendinden önceki diziden küçükse oraya yerleştirilir. Bu şekilde geriye doğru ilerlenir. Bellek işlemlerinde ve veri yerleştirilirken kullanılır. 3 10 4 6 8 9 7 2 1 5 3 10 4 3 4 10 6 3 4 6 8 10 3 4 6 8 9 10 7 2 1 5 3 4 6 7 8 9 10 2 1 5 Devam eder Algoritma: İnsertin Sort(A[0…n-1]) //Input: A[0..n−1]dizisi //Output: A[0..n−1] artan sıralı dizi for i ←1to n−1do v ←A[i] j ←i −1 while j ≥0 and A[j]>v do A[j +1]←A[j] j ←j −1 A[j +1]←v En kötü durum A[i]>v olduğu için en kötü durumda 1 karşılaştırma ve j=i-1 olduğu için en çok i-1 kere çalışır. En iyi durum Ortalama durum Ortalama durumda iki döngüde çalışacağından Arama Algoritmaları Sıralı Arama Brute force algoritmasıdır. Verilen listedeki ardışık elemanlar verilen anahtar ile karşılaştırılır. Verilen anahtar listenin sonuna eklenir. Liste arandıktan sonra anahtar listeden çıkarılır. Algoritma:SequentialSearch(A[0..n−1],K) //Input: n elemanlı a dizisi ve K anahtarı //Output: Arama sonunda ya K bulunur ya da bulunmazsa -1 döndürülür A[n]← K İ0 While A[i]=!K do i ←i +1 if i<n return i else return−1 en kötü ve ortalama durum lineardir. Binary Search Decrease and Conquer algoritmasıdır. Sıralı bir dizi için verimli arama algoritmasıdır. Ortadaki A[m] eleman ile K anahtarını karşılaştırarak çalışır. Karşılaştırma olmazsa operasyon özyinelemeli olarak K<A[m] için ilk yarısı için K>A[m] ikinci yarısı için tekrar eder. Ör: 3 14 27 31 39 42 55 70 74 81 85 93 98 K=70 arıyor. Özyinelemeli olmasına rağmen tekrarlı algoritma olarak yazılabilir. Algoritma BinarySearch(A[0..n−1],K) //Input: A[0..n−1] K anahtarı ve küçükten büyüğe sıra // Output: K ya eşit veya değilse -1 döndürülür. l←0; r ←n−1 while l≤r do m←[(l+r)/2] if K =A[m] return m else if K<A [m] r ←m−1 else l←m+1 return −1 En kötü durum Her seferinde özyinleme benzerliği ve yarısına bakılmasından dolayı 1 karşılaştırma yapılır. Cworst(n)=Cworst([n/2])+1,Cworst(1)=1. Daha az önce yerine koymayla hesaplanmıştır. N=2k Cworst(n)= Cworst(n/2)+1= Cworst(n/4)+1+1= Cworst(n/8)+1+1+1 Cworst(n)= Cworst(n/2k)+k Cworst(2k )= k+1=log2 n+1 Cworst(n)= [log2(n)]+1=[log2(n+1) En kötü durum Q(logn) Paralel Programlama Paralel Programlama Daha fazla hız Hesaplandırmaları hızlandırmak Mühendislik hesaplandırmaları DNA modelleme, hava tahmini vb. Paralel hesaplama Bir problemi birden fazla bilgisayar veya işlemci kullanarak yapılan hesaplama Paralel hesaplamanın temelleri İletişim Senkronizasyon Soru:5 bilgisayar 1 bilgisayardan 5 kat daha hızlı işlem yapar(çok doğru değil). Hızlanma S(p)=(tek işlemcide çalışma zamanı(en iyi seri algoritması))/P adet işlemcide çalışma zamanı S(p)= ts / tp S(p)= hızlanma(speed up) ifade eder. En iyi seri algoritma tek işlemcide kullanılır. P adet işlemciyle p kat hızlanabilir. Daha fazlası mümkündür. Bunun için daha fazla hafıza gerekir. Nondeterministic algoritmadır. Amdhal Yasası sistemin bir parçasının hızlandırılması sonucunda, sistemin bir bütün olarak ele alındığında toplam hızlanmasının ne olacağını hesaplamak için kullanılır. Tanım: bir algoritmanın paralel gerçeklemelerinin, seri gerçeklemesi ile arasındaki beklenen hızlanma değerlerinin ilişkisi için bir modeldir. Örneğin, eğer bir algoritmanın paralel gerçeklemeleri, algoritmanın işlemlerinin 12%'sini keyfi olarak hızlı çalıştırabiliyorsa ve işlemlerin geri kalan 88%'i paralelleştirilebilir değilse, Amdahl Yasası'na göre, paralelleştirilmiş versiyonun azami hızlanması, paralelleştirilmemiş gerçeklenmelerden Formülize edilirse işlemlerin P 'lik bir oranının etkilenerek S kadar hızlandırıldığı bir noktada erişilebilecek hızlanmayı hesaplamada kullanılır. eğer bir iyileştirme süreci, işlemlerin 30%'unu hızlandırabiliyorsa, P 0,3; ve eğer bu süreç, etkilenen bölümü eskisine göre iki kat daha hızlı çalıştırabiliyorsa, S 2 olacaktır. Amdahl Yasası'na göre, bu iyileştirmenin toplam hızlandırması; Bu formülün nasıl çıkarıldığını görmek için; eski işlem süreci süresinin 1 birim olduğunun var sayalım. Yeni işlem sürecinin alacağı zaman, hızlandırılmamış buyrukların işlenmesi için gerek süre (yani 1 - P) ile hızlandırılmış buyrukların işlenmesi için gereken sürenin toplanmasıyla elde edilir. Hızlandırılmış buyrukların işlenmesi için gereken süre, hızlandırılmış bölümün, hızlanmadan önce aldığı sürenin hızlanma katsayısına bölünmesi ile elde edilir. Örn: Bize, dört bölüme ayrılmış bir işlem verilmiş olsun, ve bu bölümlerin toplam buyruk sayısına oranları şu şekilde olsun: P1 = 11%, P2 = 18%, P3 = 23%, P4 = 48%. Görüldüğü gibi, bu oranların toplamı 100%'e ulaşmaktadır. Verilere göre, P1'de hızlanma veya yavaşlama olmamaktadır, buna göre S1 = 1 alınır. P2 5 kat hızlanmaktadır, yani S2 = 5, P3 20 kat hızlanmaktadır, yani S3 = 20, P4 ise 1.6 kat hızlanmaktadır ve S4 = 1.6 alınmaktadır Buna göre çalışma zamanı, hızlanmadan önceki zamanın yarısından biraz daha azdır. Toplam hızlanma: toplam hızlanmanın, 2 kattan biraz daha fazla olduğunu görürüz. 1-P tamamı hızlandırabildiği için (1-1)=0’dır. Ardışık Programda Hızlanma Bir bölümü kat kadar hızlandırılmış bir ardışık programın azami hızlanması, Azami Hızlanma Burada ( süredir. olarak bulunur. ), hızlandırmadan önce, hızlandırılmamış bölümün tuttuğu Örn: Eğer B bölümü (mavi) 5 kat hızlandırılırsa, p = 5 saniye ve (kırmızı) = 3 saniye, (mavi) = 1 Azami hızlanma Eğer A bölümü (kırmızı) 2 kat hızlandırılırsa, p = 2, saniye ve Azami hızlanma (mavi) = 1 saniye, (kırmızı) = 3 (Daha iyi!) A'yı 2 etmeniyle hızlandırmak, toplam program hızında +60% 'lık bir artış sağlamaktadır. B'yi 5 etmeniyle hızlandırmak ise, toplam program hızında yalnızca +25% 'lik bir artış sağlayacaktır. Çok İşlemcili Paralellik Eğer F ardışık işlemin bir parçasıyla ve (1-F) paralelleştirilebilir kısım varsa N işlemci kullanılırsa azami hızlanma olur. Limitini aldığımızda N sonsuza yönelir, azami hızlanma 1/F ’e yönelir. Uygulamada maliyet/başarım oranı, (1-F)/N, F ’ten küçük olduktan sonra N arttıkça düşer. Örn: F %10 ise problemin azami hızlanması 10’un çarpanları kadar olabilir. N ’in büyüklüğünün bir önemi yoktur. Bunun için, paralel işlem sadece ya az sayıda işlemci için ya da F ‘in çok küçük olduğu problemlerde kullanışlıdır. Paralel programlamanın büyük bir kısmı F değerini olabilecek en küçük tutar.